Tracing and Observability for LangGraph with Agenta
Learn how to monitor your LangGraph applications using Agenta's observability platform. Get complete visibility into your graph-based LLM application performance, debugging capabilities, and execution observability.
What is Agenta? Agenta is an open-source LLMOps platform designed to streamline the deployment, management, and scaling of large language models. It offers comprehensive observability, testing, and deployment capabilities for AI applications.
What is LangGraph? LangGraph is a library for building stateful, multi-actor applications with LLMs. It extends LangChain's capabilities by enabling the creation of complex workflows as directed graphs where nodes represent different processing steps and edges define the flow between them.

1. Install Required Packages
Install the necessary dependencies for the integration:
pip install agenta langchain langgraph langchain-openai langchain-community llama-index openinference-instrumentation-langchain
What each package does:
agenta: The core Agenta SDK for prompt engineering and observabilitylangchain: The LangChain framework for building LLM applicationslanggraph: Extension for creating graph-based LLM workflowslangchain-openai: OpenAI integrations for LangChainlangchain-community: Community extensions for LangChainllama-index: Document loading and processing utilitiesopeninference-instrumentation-langchain: Automatic instrumentation library for LangChain and LangGraph operations
2. Configure Your Environment
Set up your API credentials and initialize Agenta:
import os
import agenta as ag
from typing import TypedDict, Dict, Any
from langgraph.graph import StateGraph, END
from langchain_openai import ChatOpenAI
from llama_index.core import SimpleDirectoryReader
from langchain_core.runnables import RunnableLambda
from openinference.instrumentation.langchain import LangChainInstrumentor
# Load configuration from environment
os.environ["AGENTA_API_KEY"] = "your_agenta_api_key"
os.environ["AGENTA_HOST"] = "https://cloud.agenta.ai" # Optional, defaults to the Agenta cloud API
os.environ["OPENAI_API_KEY"] = "your_openai_api_key" # Required for OpenAI Agents SDK
# Initialize Agenta SDK
ag.init()
3. Enable LangChain Monitoring
Activate tarcing for all LangChain and LangGraph operations:
# Enable LangChain instrumentation (includes LangGraph)
LangChainInstrumentor().instrument()
4. Configure Language Model
Set up your language model for the LangGraph workflow:
# Configure ChatOpenAI model
llm = ChatOpenAI(model="gpt-4", temperature=0)
5. Build Your Instrumented LangGraph Application
Here's a complete example showcasing a meeting transcript analysis workflow with Agenta instrumentation:
import os
import agenta as ag
from typing import TypedDict, Dict, Any
from langgraph.graph import StateGraph, END
from langchain_openai import ChatOpenAI
from llama_index.core import SimpleDirectoryReader
from langchain_core.runnables import RunnableLambda
from openinference.instrumentation.langchain import LangChainInstrumentor
# Load environment variables
os.environ["AGENTA_API_KEY"] = "your_agenta_api_key"
os.environ["AGENTA_HOST"] = "https://cloud.agenta.ai" # Optional, defaults to the Agenta cloud API
os.environ["OPENAI_API_KEY"] = "your_openai_api_key" # Required for OpenAI Agents SDK
# Configuration setup
ag.init()
# Enable LangChain instrumentation (includes LangGraph)
LangChainInstrumentor().instrument()
# Configure language model
llm = ChatOpenAI(model="gpt-4", temperature=0)
# Define state structure for the graph
class SummarizerState(TypedDict):
input: str
segments: Dict[str, list[str]]
speaker_summaries: Dict[str, str]
actions: str
# Load meeting transcripts from documents
documents = SimpleDirectoryReader("meetings").load_data()
full_transcript = "\n".join(doc.text for doc in documents)
# Node 1: Segment speaker contributions
def segment_by_speaker(state):
transcript = state["input"]
speakers = {}
for line in transcript.split("\n"):
if ":" in line:
name, text = line.split(":", 1)
speakers.setdefault(name.strip(), []).append(text.strip())
return {**state, "segments": speakers}
# Node 2: Summarize each speaker's contributions
def summarize_per_speaker(state):
segments = state["segments"]
summaries = {}
for speaker, texts in segments.items():
joined_text = " ".join(texts)
summary = llm.invoke(f"Summarize what {speaker} said: {joined_text}")
summaries[speaker] = summary.content
return {**state, "speaker_summaries": summaries}
# Node 3: Extract action items
def extract_actions(state):
transcript = state["input"]
result = llm.invoke(f"List all action items from this transcript:\n{transcript}")
return {**state, "actions": result.content}
@ag.instrument()
def meeting_analyzer(transcript: str):
# Build LangGraph workflow
builder = StateGraph(SummarizerState)
builder.add_node("segment", RunnableLambda(segment_by_speaker))
builder.add_node("summarize", RunnableLambda(summarize_per_speaker))
builder.add_node("extract_actions", RunnableLambda(extract_actions))
builder.set_entry_point("segment")
builder.add_edge("segment", "summarize")
builder.add_edge("summarize", "extract_actions")
builder.add_edge("extract_actions", END)
graph = builder.compile()
result = graph.invoke({"input": transcript})
return result
# Example usage
if __name__ == "__main__":
result = meeting_analyzer(full_transcript)
print("Analysis Result:", result)
Understanding Span Types
The @ag.instrument() decorator helps organize your traces by categorizing different operations. Use the spankind parameter to classify your functions:
workflow(default): Complete end-to-end processesagent: Autonomous agent operationschain: Sequential processing stepstool: Utility functionsembedding: Vector embedding operationsquery: Search and retrieval operationscompletion: Text generation taskschat: Conversational interactionsrerank: Result reordering operations
Viewing Your Traces
Once your application runs, you can view detailed execution traces in Agenta's dashboard:
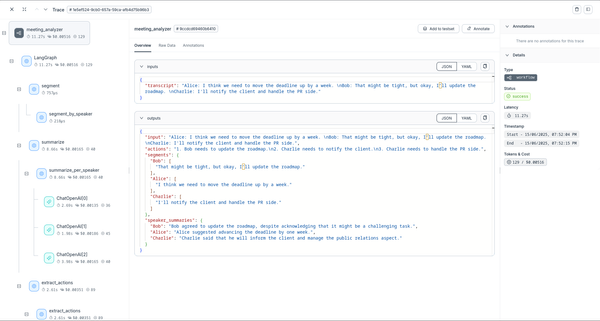
The trace provides comprehensive visibility into your application's execution, helping you:
- Debug complex graph workflows and state management
- Monitor node execution performance and bottlenecks
- Analyze LLM usage patterns and token consumption
- Track data flow and state transitions between nodes
Advanced Usage
Custom Span Configuration
Configure different instrumentation levels for various application components:
@ag.instrument(spankind="workflow")
def document_analysis_pipeline(file_path: str):
return meeting_analyzer(file_path)
@ag.instrument(spankind="tool")
def custom_document_loader(directory: str):
# Custom document loading logic
pass
@ag.instrument(spankind="chain")
def multi_step_analysis(transcript: str):
# Multi-step analysis workflow
return transcript
Real-world Examples
Customer Feedback Analysis System
class FeedbackState(TypedDict):
input: str
sentiment: str
categories: list[str]
priority: str
response_draft: str
def analyze_sentiment(state):
feedback = state["input"]
result = llm.invoke(f"Analyze sentiment of this feedback: {feedback}")
return {**state, "sentiment": result.content}
def categorize_feedback(state):
feedback = state["input"]
result = llm.invoke(f"Categorize this feedback into relevant topics: {feedback}")
return {**state, "categories": result.content.split(", ")}
def determine_priority(state):
sentiment = state["sentiment"]
categories = state["categories"]
result = llm.invoke(f"Determine priority (high/medium/low) based on sentiment: {sentiment} and categories: {categories}")
return {**state, "priority": result.content}
def draft_response(state):
feedback = state["input"]
sentiment = state["sentiment"]
result = llm.invoke(f"Draft a professional response to this {sentiment} feedback: {feedback}")
return {**state, "response_draft": result.content}
@ag.instrument()
def feedback_processor(feedback_text: str):
builder = StateGraph(FeedbackState)
builder.add_node("sentiment", RunnableLambda(analyze_sentiment))
builder.add_node("categorize", RunnableLambda(categorize_feedback))
builder.add_node("priority", RunnableLambda(determine_priority))
builder.add_node("response", RunnableLambda(draft_response))
builder.set_entry_point("sentiment")
builder.add_edge("sentiment", "categorize")
builder.add_edge("categorize", "priority")
builder.add_edge("priority", "response")
builder.add_edge("response", END)
graph = builder.compile()
return graph.invoke({"input": feedback_text})
Research Paper Analysis Pipeline
class ResearchState(TypedDict):
input: str
abstract_summary: str
key_findings: list[str]
methodology: str
limitations: str
relevance_score: float
@ag.instrument()
def research_analyzer(paper_text: str):
def extract_abstract(state):
paper = state["input"]
result = llm.invoke(f"Extract and summarize the abstract from this research paper: {paper}")
return {**state, "abstract_summary": result.content}
def identify_findings(state):
paper = state["input"]
result = llm.invoke(f"List the key findings from this research paper: {paper}")
return {**state, "key_findings": result.content.split("\n")}
def analyze_methodology(state):
paper = state["input"]
result = llm.invoke(f"Describe the methodology used in this research: {paper}")
return {**state, "methodology": result.content}
def assess_limitations(state):
paper = state["input"]
result = llm.invoke(f"Identify limitations mentioned in this research: {paper}")
return {**state, "limitations": result.content}
def score_relevance(state):
abstract = state["abstract_summary"]
result = llm.invoke(f"Rate the relevance of this research on a scale of 0-10: {abstract}")
try:
score = float(result.content.strip())
except:
score = 5.0
return {**state, "relevance_score": score}
builder = StateGraph(ResearchState)
builder.add_node("abstract", RunnableLambda(extract_abstract))
builder.add_node("findings", RunnableLambda(identify_findings))
builder.add_node("methodology", RunnableLambda(analyze_methodology))
builder.add_node("limitations", RunnableLambda(assess_limitations))
builder.add_node("relevance", RunnableLambda(score_relevance))
builder.set_entry_point("abstract")
builder.add_edge("abstract", "findings")
builder.add_edge("findings", "methodology")
builder.add_edge("methodology", "limitations")
builder.add_edge("limitations", "relevance")
builder.add_edge("relevance", END)
graph = builder.compile()
return graph.invoke({"input": paper_text})
Content Moderation Workflow
class ModerationState(TypedDict):
input: str
toxicity_score: float
content_categories: list[str]
action_required: str
explanation: str
@ag.instrument()
def content_moderator(user_content: str):
def assess_toxicity(state):
content = state["input"]
result = llm.invoke(f"Rate toxicity of this content from 0-10: {content}")
try:
score = float(result.content.strip())
except:
score = 0.0
return {**state, "toxicity_score": score}
def categorize_content(state):
content = state["input"]
result = llm.invoke(f"Categorize this content (spam, harassment, hate speech, etc.): {content}")
return {**state, "content_categories": result.content.split(", ")}
def determine_action(state):
toxicity = state["toxicity_score"]
categories = state["content_categories"]
if toxicity > 7:
action = "remove"
elif toxicity > 4:
action = "flag_for_review"
else:
action = "approve"
explanation = f"Decision based on toxicity score: {toxicity} and categories: {categories}"
return {**state, "action_required": action, "explanation": explanation}
builder = StateGraph(ModerationState)
builder.add_node("toxicity", RunnableLambda(assess_toxicity))
builder.add_node("categorize", RunnableLambda(categorize_content))
builder.add_node("action", RunnableLambda(determine_action))
builder.set_entry_point("toxicity")
builder.add_edge("toxicity", "categorize")
builder.add_edge("categorize", "action")
builder.add_edge("action", END)
graph = builder.compile()
return graph.invoke({"input": user_content})
Next Steps
For more advanced observability features and configuration options, see our complete observability documentation.