Configure Evaluators
In this guide will show you how to configure evaluators for your LLM application.
What are evaluators?
Evaluators are functions that assess the output of an LLM application.
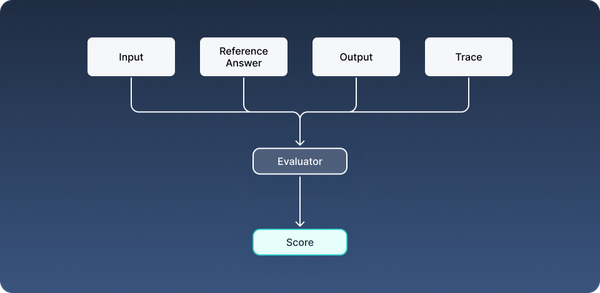
Evaluators typically take as input:
- The output of the LLM application
- (Optional) The reference answer (i.e., expected output or ground truth)
- (Optional) The inputs to the LLM application
- Any other relevant data, such as context
Evaluators return either a float or a boolean value.
Configuring evaluators
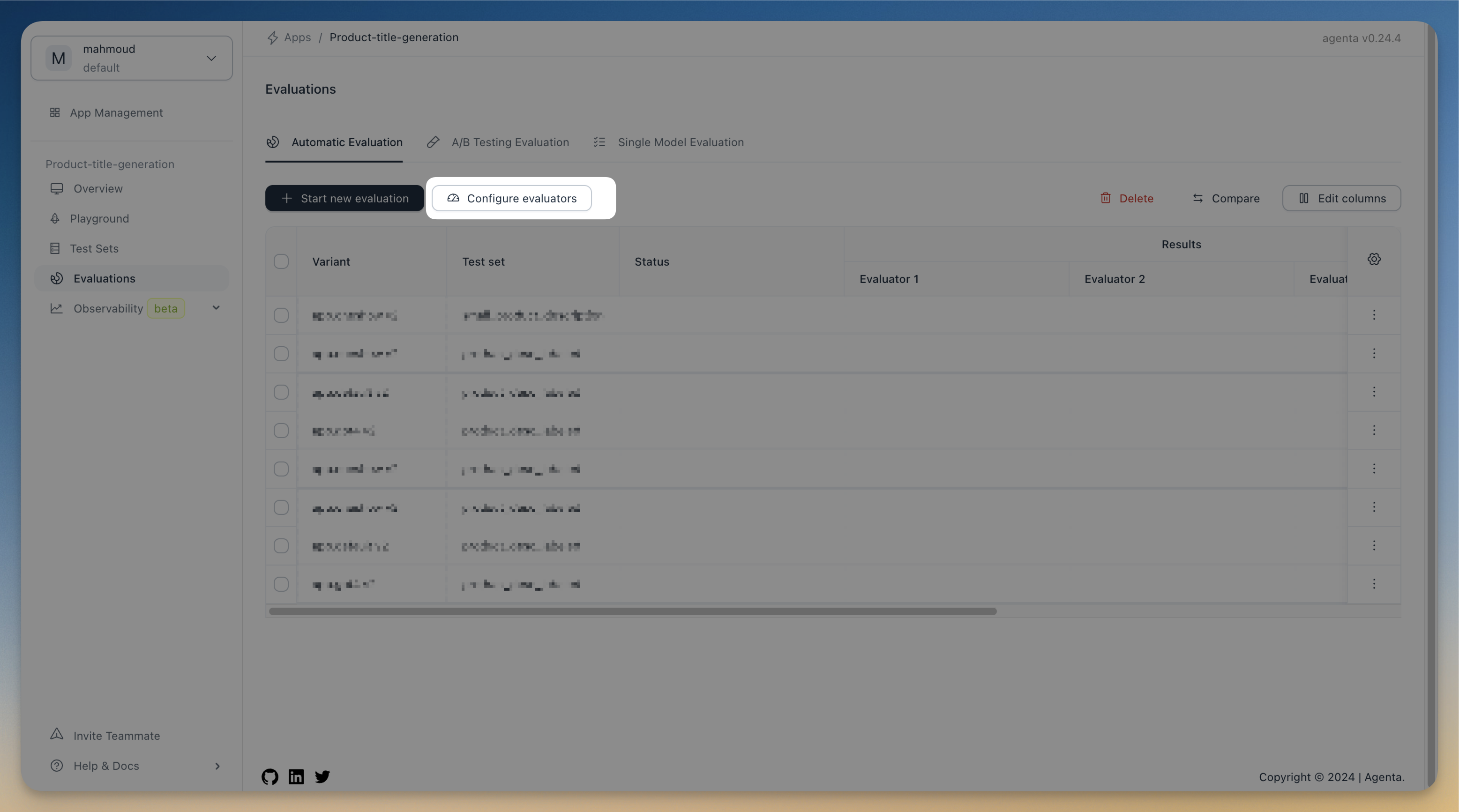
To create a new evaluator, click on the Configure Evaluators button in the Evaluations view.
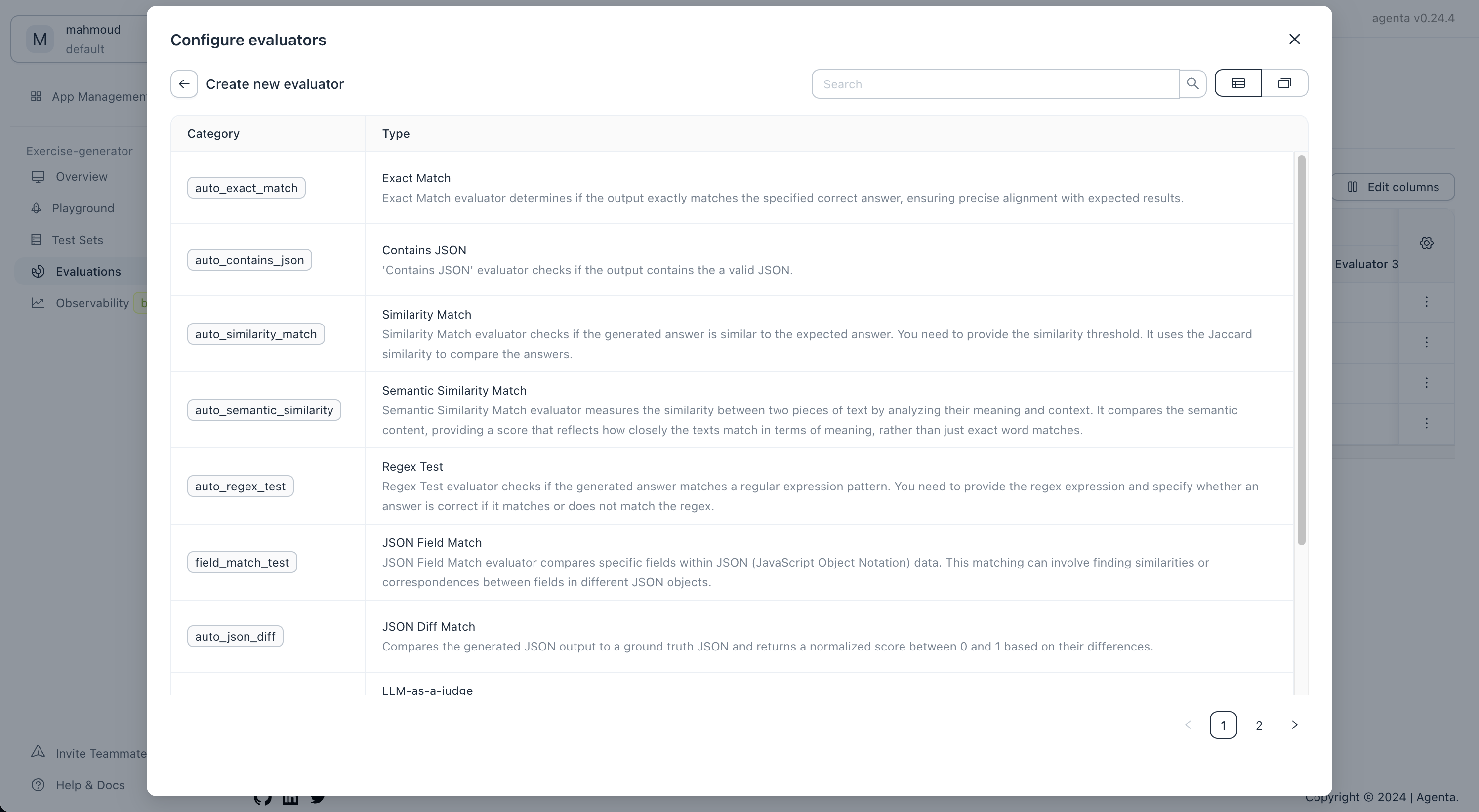
Selecting evaluators
Agenta offers a growing list of pre-built evaluators suitable for most use cases. We also provide options for creating custom evaluators (by writing your own Python function) or using webhooks for evaluation.
Available Evaluators
| Evaluator Name | Use Case | Type | Description |
|---|---|---|---|
| Exact Match | Classification/Entity Extraction | Pattern Matching | Checks if the output exactly matches the expected result. |
| Contains JSON | Classification/Entity Extraction | Pattern Matching | Ensures the output contains valid JSON. |
| Regex Test | Classification/Entity Extraction | Pattern Matching | Checks if the output matches a given regex pattern. |
| JSON Field Match | Classification/Entity Extraction | Pattern Matching | Compares specific fields within JSON data. |
| JSON Diff Match | Classification/Entity Extraction | Similarity Metrics | Compares generated JSON with a ground truth JSON based on schema or values. |
| Similarity Match | Text Generation / Chatbot | Similarity Metrics | Compares generated output with expected using Jaccard similarity. |
| Semantic Similarity Match | Text Generation / Chatbot | Semantic Analysis | Compares the meaning of the generated output with the expected result. |
| Starts With | Text Generation / Chatbot | Pattern Matching | Checks if the output starts with a specified prefix. |
| Ends With | Text Generation / Chatbot | Pattern Matching | Checks if the output ends with a specified suffix. |
| Contains | Text Generation / Chatbot | Pattern Matching | Checks if the output contains a specific substring. |
| Contains Any | Text Generation / Chatbot | Pattern Matching | Checks if the output contains any of a list of substrings. |
| Contains All | Text Generation / Chatbot | Pattern Matching | Checks if the output contains all of a list of substrings. |
| Levenshtein Distance | Text Generation / Chatbot | Similarity Metrics | Calculates the Levenshtein distance between output and expected result. |
| LLM-as-a-judge | Text Generation / Chatbot | LLM-based | Sends outputs to an LLM model for critique and evaluation. |
| RAG Faithfulness | RAG / Text Generation / Chatbot | LLM-based | Evaluates if the output is faithful to the retrieved documents in RAG workflows. |
| RAG Context Relevancy | RAG / Text Generation / Chatbot | LLM-based | Measures the relevancy of retrieved documents to the given question in RAG. |
| Custom Code Evaluation | Custom Logic | Custom | Allows users to define their own evaluator in Python. |
| Webhook Evaluator | Custom Logic | Custom | Sends output to a webhook for external evaluation. |
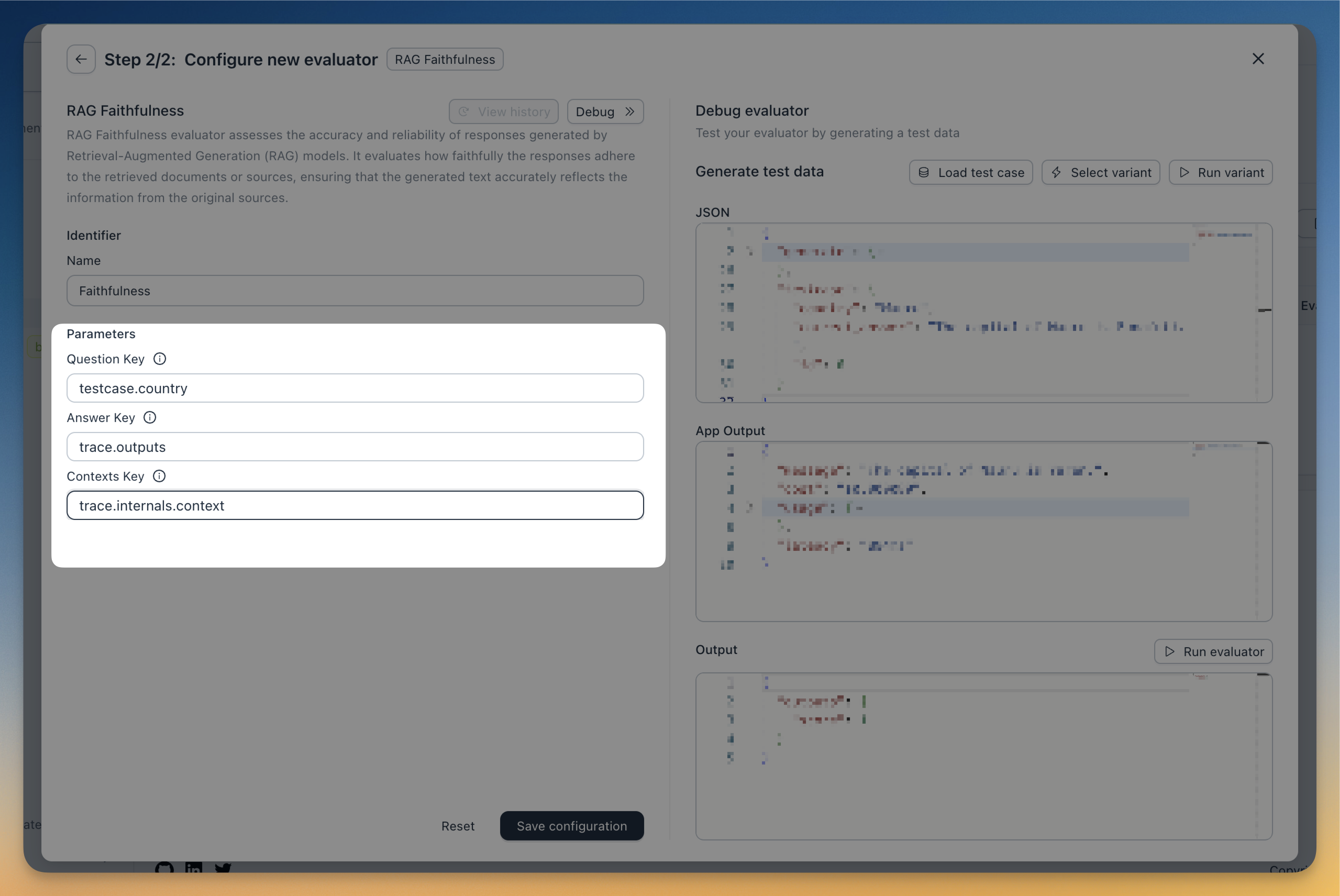
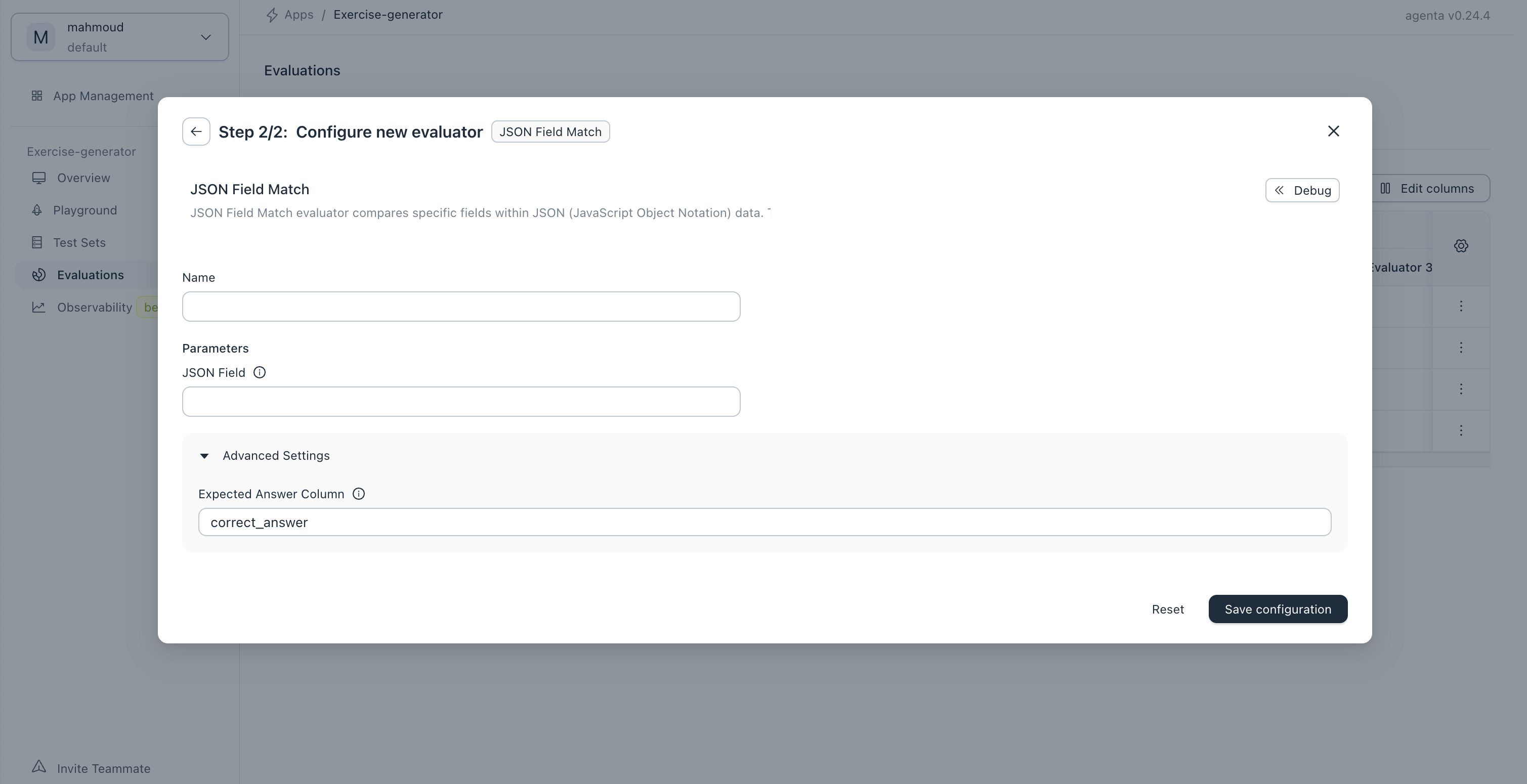
Evaluators' settings
Each evaluator comes with it's unique settings. For instance in the screen below, the JSON field match evaluator requires you to specify which field in the output JSON you need to consider for evaluation. You'll find detailed information about these parameters on each evaluator's documentation page.
Mappings evaluator's inputs to the LLM data
Evaluators need to know which parts of the data contain the output and the reference answer. Most evaluators allow you to configure this mapping, typically by specifying the name of the column in the test set that contains the reference answer.
For more sophisticated evaluators, such as RAG evaluators (available only in cloud and enterprise versions), you need to define more complex mappings (see figure below).
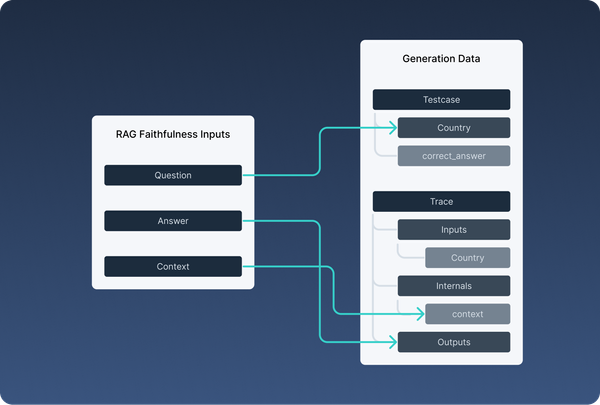
Configuring the evaluator is done by mapping the evaluator inputs to the generation data: