Quick Start
Agenta enables you to capture all inputs, outputs, and metadata from your LLM applications, whether they're hosted within Agenta or running in your own environment.
This guide will walk you through setting up observability for an OpenAI application running locally.
note
If you create an application through the Agenta UI, tracing is enabled by default. No additional setup is required—simply go to the observability view to see all your requests.
Step-by-Step Guide
1. Install Required Packages
First, install the Agenta SDK, OpenAI, and the OpenTelemetry instrumentor for OpenAI:
pip install -U agenta openai opentelemetry-instrumentation-openai
2. Configure Environment Variables
- Agenta Cloud or Enterprise
- Agenta OSS Running Locally
If you're using Agenta Cloud or Enterprise Edition, you'll need an API key:
- Visit the Agenta API Keys page.
- Click on Create New API Key and follow the prompts.
import os
os.environ["AGENTA_API_KEY"] = "YOUR_AGENTA_API_KEY"
os.environ["AGENTA_HOST"] = "https://cloud.agenta.ai"
import os
os.environ["AGENTA_HOST"] = "http://localhost"
3. Instrument Your Application
Below is a sample script to instrument an OpenAI application:
import agenta as ag
from opentelemetry.instrumentation.openai import OpenAIInstrumentor
import openai
ag.init()
OpenAIInstrumentor().instrument()
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Write a short story about AI Engineering."},
],
)
print(response.choices[0].message.content)
Explanation:
- Import Libraries: Import Agenta, OpenAI, and the OpenTelemetry instrumentor.
- Initialize Agenta: Call
ag.init()to initialize the Agenta SDK. - Instrument OpenAI: Use
OpenAIInstrumentor().instrument()to enable tracing for OpenAI calls.
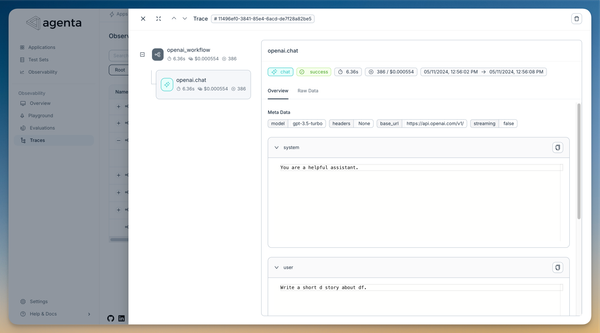
4. View Traces in the Agenta UI
After running your application, you can view the captured traces in Agenta:
- Log in to your Agenta dashboard.
- Navigate to the Observability section.
- You'll see a list of traces corresponding to your application's requests.