Overview
Building LLM-powered applications is an iterative process. In each iteration, you aim to improve the application's performance by refining prompts, adjusting configurations, and evaluating outputs.
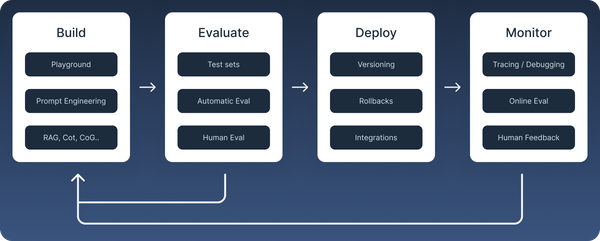
Why do I need a prompt management system?
A prompt management system enables everyone on the team—from product owners to subject matter experts—to collaborate in creating prompts. Additionally it helps you answer the following questions:
- Which prompts have we tried?
- What were the outputs of these prompts?
- How do the evaluation results of these prompts compare?
- Which prompt version was used for a specific generation in production?
- What was the effect of publishing the new version of this prompt in production?
- Who on the team made changes to a particular prompt version in production?
Features in agenta
Agenta provides you with the following capabilities:
- A playground where developers and subject matter experts can collaboratively create and test prompts and compare models
- A prompt management system where, you can:
- Versioning Prompts: Keeping track of different prompts you've tested and a history of changes in production.
- Linking Prompts to Experiments: Connecting each prompt version to its evaluation metrics to understand the effect of changes and determine the best variant.
- Linking Prompts to Traces: Monitoring how changes in prompt versions affect the traces and production metrics.
Agenta goes beyond prompt management to encompass the entire configuration of your LLM applications. If your LLM workflow is more complex than a single prompt (e.g., Retrieval-Augmented Generation (RAG) or a chain of prompts), you can version the whole configuration together.
In contrast to a prompt, a configuration of an LLM application can include additional parameters beyond prompt templates and models (with their parameters). For instance:
- An LLM application using a chain of two prompts would have a configuration that includes the two prompts and their respective model parameters.
- An application that includes a RAG pipeline would have a configuration that includes parameters such as
top_kandembedding.
{
"top_k": 3,
"embedding": "text-embedding-3-large",
"prompt-query": "We have provided context information below. {context_str}. Given this information, please answer the question: {query_str}\n",
"model-query": "openai/gpt-o1",
"temperature-query": "1.0"
}
Get started
📄️ Explore the Prompt Management SDK
Learn advanced features of the prompt management SDK
📄️ Explore the Playground
Learn how to use the playground