Tracing and Observability for LlamaIndex with Agenta
Learn how to monitor your LlamaIndex applications using Agenta's observability platform. Get complete visibility into your document search, RAG pipelines, and LLM interactions.
What is Agenta? Agenta is an open-source LLMOps platform designed to streamline the deployment, management, and scaling of large language models. It offers comprehensive observability, testing, and deployment capabilities for AI applications.
What is LlamaIndex? LlamaIndex (GitHub) is a powerful data framework that connects LLMs with your private data sources. It simplifies working with various data formats (PDFs, APIs, databases, documents) and creates searchable indices for context-aware AI applications.

1. Install Required Packages
Install the necessary dependencies for the integration:
pip install agenta llama_index openinference-instrumentation-llama_index
What each package does:
agenta: Core SDK for observability and prompt managementllama_index: Framework for building data-aware LLM applicationsopeninference-instrumentation-llama_index: Automatic tracing for LlamaIndex operations
2. Configure Your Environment
Set up your API credentials and initialize Agenta:
import os
import agenta as ag
# Set your Agenta credentials
os.environ["AGENTA_API_KEY"] = "your_agenta_api_key"
os.environ["AGENTA_HOST"] = "https://cloud.agenta.ai" # Use your self-hosted URL if applicable
# Initialize Agenta SDK
ag.init()
3. Enable Automatic Tracing
Activate monitoring for all LlamaIndex operations:
from openinference.instrumentation.llama_index import LlamaIndexInstrumentor
# Start automatic instrumentation
LlamaIndexInstrumentor().instrument()
Once this is set up, Agenta will automatically capture:
- Document loading and processing steps
- Vector index creation and updates
- Search queries and retrieval operations
- LLM calls for response generation
Build Your Instrumented Application
Here's a complete example of a LlamaIndex application with Agenta instrumentation:
import os
import agenta as ag
from openinference.instrumentation.llama_index import LlamaIndexInstrumentor
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
# Configuration setup
os.environ["AGENTA_API_KEY"] = "your_agenta_api_key"
os.environ["AGENTA_HOST"] = "https://cloud.agenta.ai" # Optional, defaults to the Agenta cloud API
# Start Agenta observability
ag.init()
# Enable LlamaIndex instrumentation
LlamaIndexInstrumentor().instrument()
@ag.instrument()
def document_search_app(user_query: str):
"""
Document search application using LlamaIndex.
Loads documents, builds a searchable index, and answers user queries.
"""
# Load documents from local directory
docs = SimpleDirectoryReader("data").load_data()
# Build vector search index
search_index = VectorStoreIndex.from_documents(docs)
# Initialize query processor
query_processor = search_index.as_query_engine()
# Process user query
answer = query_processor.query(user_query)
return answer
# Run the application
if __name__ == "__main__":
result = document_search_app("What is Agenta?")
print(f"Answer: {result}")
Understanding Span Types
The @ag.instrument() decorator helps organize your traces by categorizing different operations. Use the spankind parameter to classify your functions:
Available Span Types
workflow(default): Complete end-to-end processesagent: Autonomous agent operationschain: Sequential processing stepstool: Utility functionsembedding: Vector embedding operationsquery: Search and retrieval operationscompletion: Text generation taskschat: Conversational interactionsrerank: Result reordering operations
Example with Span Classification
@ag.instrument(spankind="workflow")
def main_search_pipeline(question: str):
"""Main search workflow - will appear as the top-level process"""
documents = load_documents()
index = create_index(documents)
return search_and_respond(index, question)
@ag.instrument(spankind="embedding")
def create_index(documents):
"""Document indexing - will appear as an embedding operation"""
return VectorStoreIndex.from_documents(documents)
@ag.instrument(spankind="query")
def search_and_respond(index, question):
"""Search execution - will appear as a query operation"""
engine = index.as_query_engine()
return engine.query(question)
Viewing Your Traces
Once your application runs, you can view detailed execution traces in Agenta's dashboard:
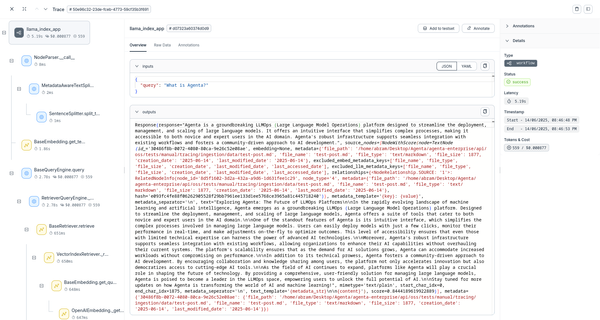
What You'll See in the Dashboard
Execution Timeline: Complete workflow from query to response Performance Metrics: Timing for each operation step Document Processing: How documents are loaded and indexed Search Operations: Vector similarity searches and retrieval LLM Interactions: Calls to language models for response generation Error Tracking: Any failures or exceptions in the pipeline
This visibility helps you:
- Optimize Performance: Identify slow operations and bottlenecks
- Debug Issues: See exactly where problems occur in your pipeline
- Monitor Usage: Track query patterns and response quality
- Improve Accuracy: Understand how well document retrieval is working
Advanced Usage
Custom Span Configuration
Configure different instrumentation levels for various application components:
@ag.instrument(spankind="workflow")
def main_processing_pipeline(query: str):
return document_search_app(query)
@ag.instrument(spankind="embedding")
def generate_document_embeddings(documents):
# Custom embedding generation logic
pass
@ag.instrument(spankind="query")
def execute_search_query(engine, query):
# Custom search execution
return engine.query(query)
Real-world Examples
Knowledge Base Assistant
@ag.instrument(spankind="workflow")
def knowledge_assistant(question: str, docs_path: str):
documents = SimpleDirectoryReader(docs_path).load_data()
index = VectorStoreIndex.from_documents(documents)
engine = index.as_query_engine()
return engine.query(question)
Multi-Step RAG Pipeline
@ag.instrument(spankind="chain")
def rag_pipeline(query: str):
# Step 1: Document retrieval
retrieved_docs = retrieve_documents(query)
# Step 2: Context augmentation
augmented_context = augment_context(retrieved_docs)
# Step 3: Response generation
response = generate_response(query, augmented_context)
return response
Next Steps
For more advanced observability features and configuration options, see our complete observability documentation.