Tracing and Observability for DSPy with Agenta
Learn how to connect Agenta with DSPy for complete visibility into your LLM application performance, debugging capabilities, and execution observability.
What is Agenta? Agenta is an open-source LLMOps platform designed to streamline the deployment, management, and scaling of large language models. It offers comprehensive observability, testing, and deployment capabilities for AI applications.
What is DSPy? DSPy (GitHub) is a framework for algorithmically optimizing LM prompts and weights. It provides composable and declarative modules for instructing language models in a more systematic way than traditional prompting.

Setup Guide
Follow these steps to integrate DSPy with Agenta's observability platform for real-time tracing and performance analysis.
Install Required Packages
First, install the required dependencies. These packages are essential for the integration:
pip install agenta dspy openinference-instrumentation-dspy
Package Overview:
agenta: The core Agenta SDK for prompt engineering and observabilitydspy: The DSPy framework for building systematic LLM applicationsopeninference-instrumentation-dspy: Automatic instrumentation library for DSPy operations
Setup and Configuration
Initialize your environment and configure the Agenta SDK:
import os
import agenta as ag
import dspy
from openinference.instrumentation.dspy import DSPyInstrumentor
# Load configuration from environment
os.environ["AGENTA_API_KEY"] = "your_agenta_api_key"
os.environ["AGENTA_HOST"] = "https://cloud.agenta.ai" # Optional, defaults to the Agenta cloud API
os.environ["OPENAI_API_KEY"] = "your_openai_api_key" # Required for OpenAI models
# Start Agenta SDK
ag.init()
What does
ag.init()do? Theag.init()function initializes the Agenta SDK and sets up the necessary configuration for observability. It establishes connection to the Agenta platform, configures tracing and logging settings, and prepares the instrumentation context for your application.
Enable DSPy Monitoring
Initialize the OpenInference DSPy instrumentation to automatically capture DSPy operations:
# Enable DSPy instrumentation
DSPyInstrumentor().instrument()
Configure DSPy Language Model
Set up your DSPy language model configuration:
# Configure DSPy with your preferred language model
lm = dspy.LM("openai/gpt-4o")
dspy.configure(lm=lm)
Build Your Instrumented Application
Here's a complete example showcasing three different DSPy use cases with Agenta instrumentation:
import os
import agenta as ag
import dspy
from openinference.instrumentation.dspy import DSPyInstrumentor
# Configuration setup
os.environ["AGENTA_API_KEY"] = "your_agenta_api_key"
os.environ["AGENTA_HOST"] = "https://cloud.agenta.ai" # Optional, defaults to the Agenta cloud API
os.environ["OPENAI_API_KEY"] = "your_openai_api_key" # Required for OpenAI models
# Start Agenta observability
ag.init()
# Enable DSPy instrumentation
DSPyInstrumentor().instrument()
# Configure DSPy
lm = dspy.LM("openai/gpt-4o")
dspy.configure(lm=lm)
# Use case 1: Math reasoning with Chain of Thought (CoT)
@ag.instrument()
def math_reasoning(question: str):
cot = dspy.ChainOfThought("question -> answer: float")
response = cot(question=question)
return response
# Use case 2: Retrieval-Augmented Generation (RAG) with Wikipedia search
@ag.instrument(spankind="query")
def search_wikipedia(query: str) -> list[str]:
results = dspy.ColBERTv2(url="http://20.102.90.50:2017/wiki17_abstracts")(
query, k=3
)
return [x["text"] for x in results]
@ag.instrument()
def rag(question: str):
cot = dspy.ChainOfThought("context, question -> response")
response = cot(context=search_wikipedia(question), question=question)
return response
# Use case 3: Drafting an article with an outline and sections
class Outline(dspy.Signature):
"""Outline a thorough overview of a topic."""
topic: str = dspy.InputField()
title: str = dspy.OutputField()
sections: list[str] = dspy.OutputField()
section_subheadings: dict[str, list[str]] = dspy.OutputField(
desc="mapping from section headings to subheadings"
)
class DraftSection(dspy.Signature):
"""Draft a top-level section of an article."""
topic: str = dspy.InputField()
section_heading: str = dspy.InputField()
section_subheadings: list[str] = dspy.InputField()
content: str = dspy.OutputField(desc="markdown-formatted section")
class DraftArticle(dspy.Module):
def __init__(self):
self.build_outline = dspy.ChainOfThought(Outline)
self.draft_section = dspy.ChainOfThought(DraftSection)
def forward(self, topic: str):
outline = self.build_outline(topic=topic)
sections = []
for heading, subheadings in outline.section_subheadings.items():
section, subheadings = f"## {heading}", [
f"### {subheading}" for subheading in subheadings
]
section = self.draft_section(
topic=outline.title,
section_heading=section,
section_subheadings=subheadings,
)
sections.append(section.content)
return dspy.Prediction(title=outline.title, sections=sections)
@ag.instrument()
def journalist(topic: str):
draft_article = DraftArticle()
article = draft_article(topic=topic)
return article
# Example usage
if __name__ == "__main__":
# Use case 1: Math reasoning
response = math_reasoning("What is 2 + 2?")
print("Math reasoning response:", response)
# Use case 2: RAG with Wikipedia
rag_response = rag("What's the name of the castle that David Gregory inherited?")
print("RAG response:", rag_response)
# Use case 3: Article generation
article = journalist("The impact of AI on society")
print("Article generation response:", article)
Understanding the @ag.instrument() Decorator
The @ag.instrument() decorator automatically captures all input and output data from your function, enabling comprehensive observability without manual instrumentation.
Span Classification:
Use the spankind parameter to categorize different operations in Agenta WebUI. Available classifications:
agent- Autonomous agent operationschain- Sequential processing workflowsworkflow- End-to-end application flows (default behavior)tool- Utility function executionsembedding- Vector embedding operationsquery- Search and retrieval operationscompletion- Text generation taskschat- Conversational interactionsrerank- Result reordering operations
Standard Behavior:
By default, when spankind is not specified, the operation becomes a root-level span, categorized as a workflow in Agenta.
Example with specific span kind:
@ag.instrument(spankind="query")
def search_knowledge_base(search_term: str):
# Knowledge base search implementation
pass
View Traces in Agenta
Once your application runs, access detailed execution traces through Agenta's dashboard. The observability data includes:
- End-to-end workflow execution timeline
- DSPy module initialization and configuration steps
- Chain of Thought reasoning processes
- Retrieval operations and context augmentation
- Language model calls and response generation
- Performance metrics and execution duration
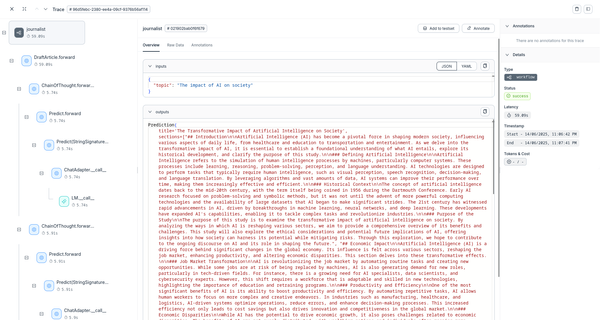
The trace provides comprehensive visibility into your application's execution, helping you:
- Debug complex reasoning chains and prompt optimization
- Monitor retrieval effectiveness and context quality
- Analyze language model performance and token usage
- Track application behavior trends and optimization opportunities
Advanced Usage
Custom Span Configuration
Configure different instrumentation levels for various application components:
@ag.instrument(spankind="workflow")
def complex_reasoning_pipeline(query: str):
return math_reasoning(query)
@ag.instrument(spankind="tool")
def custom_retrieval_function(query: str):
# Custom retrieval logic
pass
@ag.instrument(spankind="chain")
def multi_step_reasoning(question: str):
# Multi-step reasoning implementation
return question
Next Steps
For more detailed information about Agenta's observability features and advanced configuration options, visit the Agenta Observability SDK Documentation.