Evaluating LLM Apps
Systematically evaluate your LLM applications and compare their performance.
The key to building production-ready LLM applications is to have a tight feedback loop of prompt engineering and evaluation. In this document, we will explain how to use agenta to quickly evaluate and compare the performance of your LLM applications.
Configuring Evaluators
Agenta comes with a set of built-in evaluators that can be configured.
By default, each project includes the following evaluators (which do not require configuration):
- Exact match: This evaluator checks if the generated answer is an exact match to the expected answer. The aggregated result is the percentage of correct answers.
Additionally, the following configurable evaluators are available but need to be explicitly configured and added before use.
To add an evaluator, go to the Evaluators tab and click on the “Add Evaluator” button. A modal will appear where you can select the evaluator you want to add and configure it.
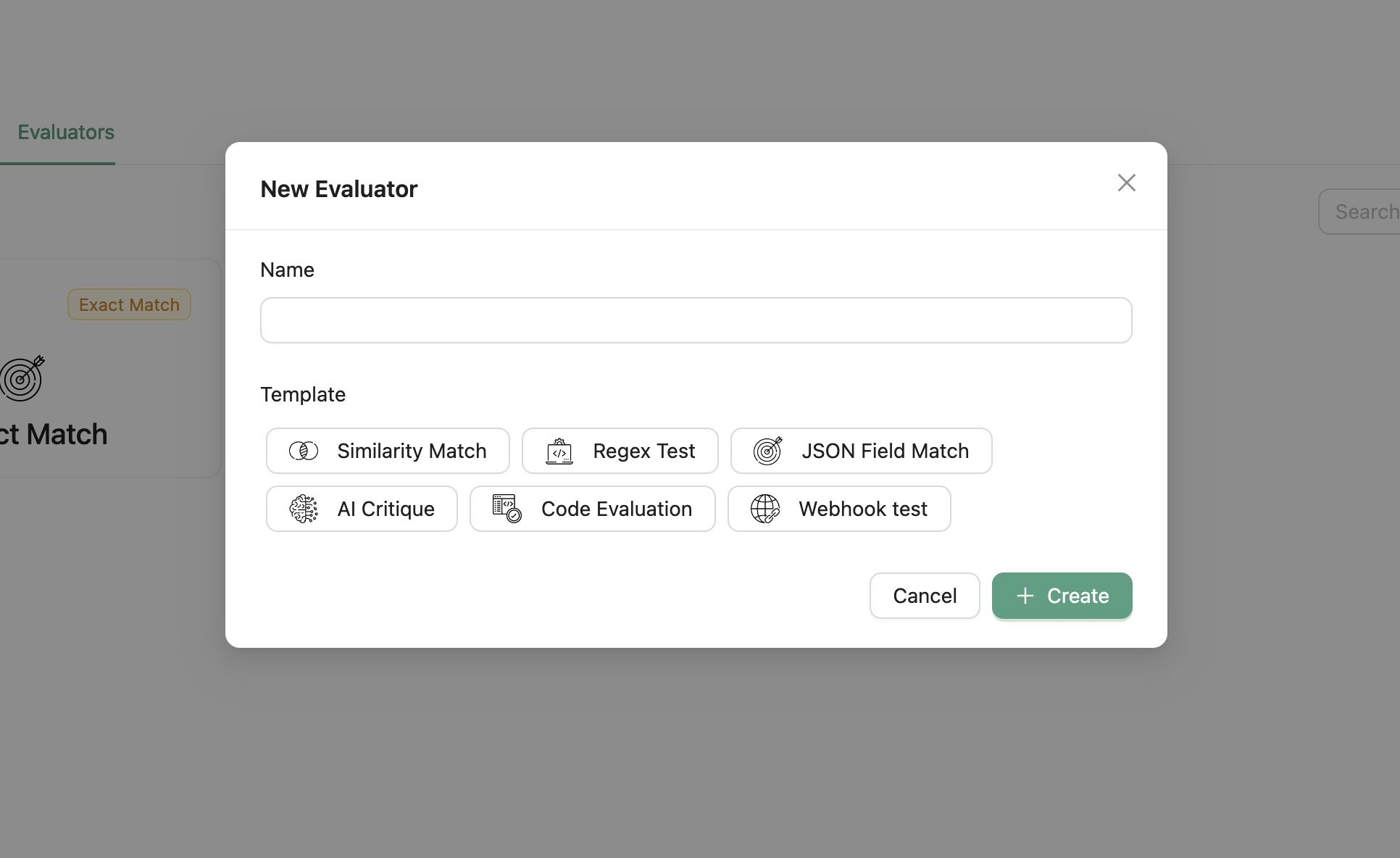
Configurable evaluators
- Regex match: This evaluator checks if the generated answer matches a regular expression pattern. You need to provide the regex expression and specify whether an answer is correct if it matches or does not match the regex.
- Webhook evaluator: This evaluator sends the generated answer and the correct_answer to a webhook and expects a response indicating the correctness of the answer. You need to provide the URL of the webhook.
- Similarity Match evaluator: This evaluator checks if the generated answer is similar to the expected answer. You need to provide the similarity threshold. It uses the Jaccard similarity to compare the answers.
- AI Critic evaluator: This evaluator sends the generated answer and the correct_answer to an LLM model and uses it to evaluate the correctness of the answer. You need to provide the evaluation prompt (or use the default prompt).
- Custom code evaluator: This evaluator allows you to write your own evaluator in Python. You need to provide the Python code for the evaluator. More details can be found here.
Begin Evaluation
To start an evaluation, go to the Evaluations page and click on the “Begin Evaluation Now” button. A modal will appear where you can fine-tune the evaluation based on your specific requirements.
In the modal, you need to specify the following parameters:
- Testset: Choose the testset you want to use for the evaluation.
- Variants: Select one or more variants you wish to evaluate.
- Evaluators: Choose one or more evaluators for the assessment.


Advanced Configuration
Additional configurations for batching and retrying LLM calls are available in the advanced configuration section. You can specify the following parameters:
- Batch Size: Set the number of testsets to include in each batch (default is 10).
- Retry Delay: Define the delay before retrying a failed language model call (in seconds, default is 3).
- Max Retries: Specify the maximum number of retries for a failed language model call (default is 3).
- Delay Between Batches: Set the delay between running batches (in seconds, default is 5).
In addition to the batching and retrying configurations, you can also specify the following parameters:
- Correct Answer Column: Specify the column in the test set containing the correct/expected answer (default is correct_answer).


View Evaluation Result
To view the result of an evaluation, double-click on the evaluation row once you have clicked the “Create” button and the evaluation status is set to “completed”. This will give you access to the detailed evaluation results.


Compare Evaluations
When the evaluation status is set to “completed”, you can select two or more evaluations from the same testset to compare. Click on the “Compare” button, and you will be taken to the Evaluation comparison view where you can compare the output of two or more evaluations.


Was this page helpful?