What is Agenta?
The open-source end-to-end LLMOps platform.

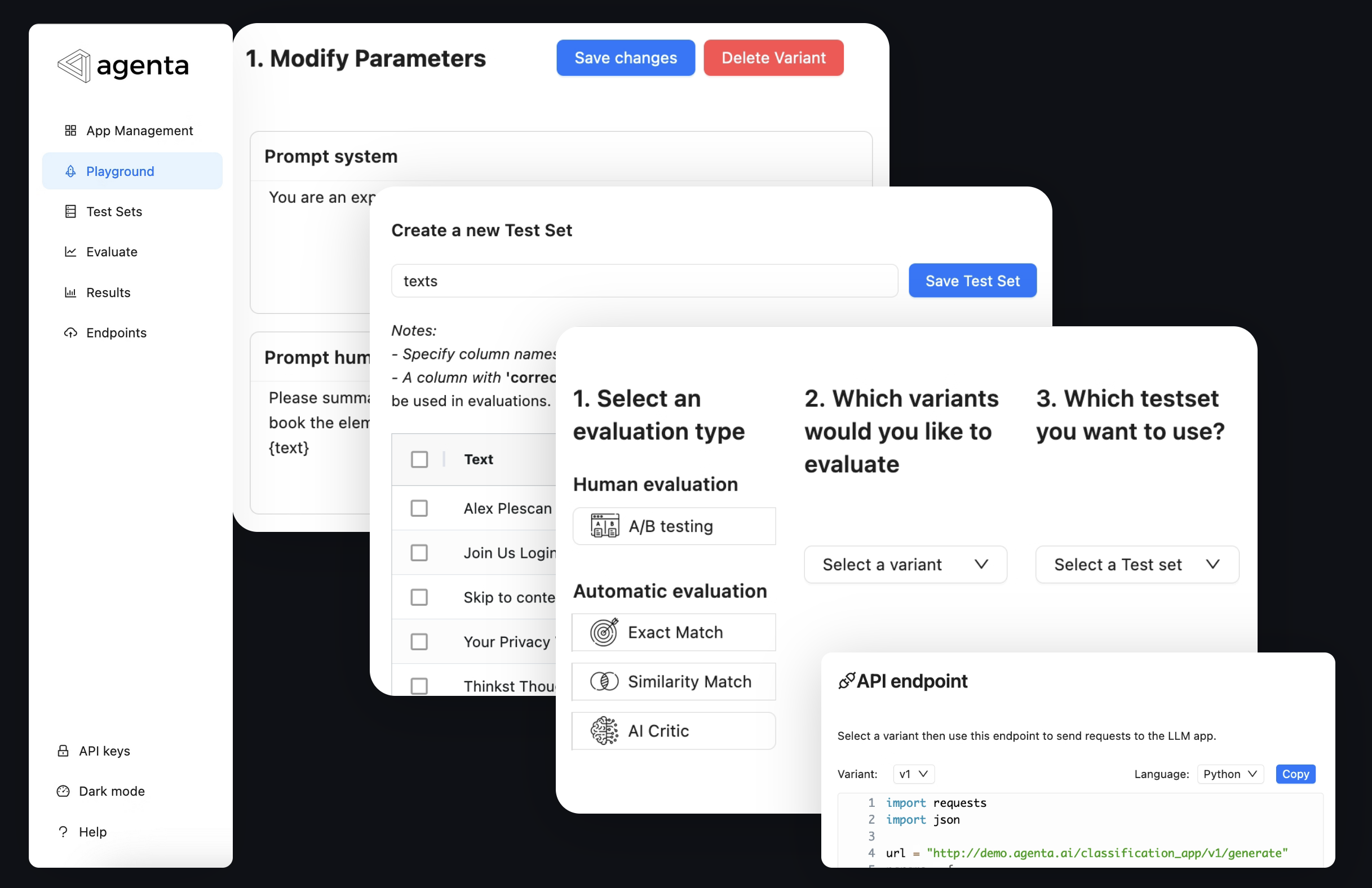
Agenta is an open-source platform that helps developers and product teams build robust AI applications powered by LLMs. It offers all the tools for prompt management and evaluation.
With Agenta, you can:
- Rapidly experiment and compare prompts on any LLM workflow (chain-of-prompts, Retrieval Augmented Generation (RAG), LLM agents…)
- Rapidly create test sets and golden datasets for evaluation
- Evaluate your application with pre-existing or custom evaluators
- Annotate and A/B test your applications with human feedback
- Collaborate with product teams for prompt engineering and evaluation
- Deploy your application in one-click in the UI, through CLI, or through github workflows.
Agenta focuses on increasing the speed of the development cycle of LLM applications by increasing the speed of experimentation.
How is Agenta different?
Works with any LLM app workflow
Agenta enables prompt engineering and evaluation on any LLM app architecture, such as Chain of Prompts, RAG, or LLM agents. It is compatible with any framework like Langchain or LlamaIndex, and works with any model provider, such as OpenAI, Cohere, or local models.
Jump here to see how to use your own custom application with Agenta and here to understand more how Agenta works.
Enable collaboration between developers and product teams
Agenta empowers non-developers to iterate on the configuration of any custom LLM application, evaluate it, annotate it, A/B test it, and deploy it, all within the user interface.
By adding a few lines to your application code, you can create a prompt playground that allows non-developers to experiment with prompts for your application and use all the tools within Agenta.
Next Steps
Get Started
Create and deploy your first app from the UI in under 2 minutes.
Create a Custom App
Write a custom LLM app and evaluate it in 10 minutes.
Getting Help
If you have questions or need support, here’s how you can reach us.
Was this page helpful?