Observability and Prompt Management
This release is one of our biggest yet—one changelog hardly does it justice.
First up: Observability
We’ve had observability in beta for a while, but now it’s been completely rewritten, with a brand-new UI and fully open-source code.
The new Observability SDK is compatible with OpenTelemetry (Otel) and gen-ai semantic conventions. This means you get a lot of integrations right out of the box, like LangChain, OpenAI, and more.
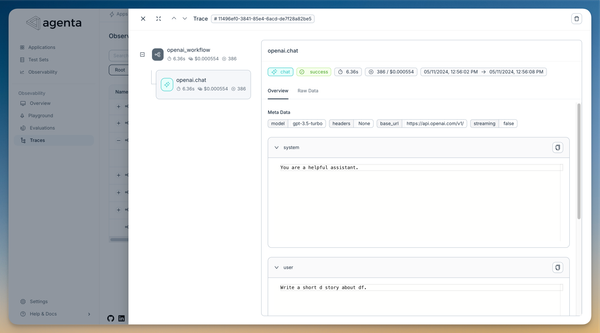
We’ll publish a full blog post soon, but here’s a quick look at what the new observability offers:
-
A redesigned UI that lets you visualize nested traces, making it easier to understand what’s happening behind the scenes.
-
The web UI lets you filter traces by name, cost, and other attributes—you can even search through them easily.
-
The SDK is Otel-compatible, and we’ve already tested integrations for OpenAI, LangChain, LiteLLM, and Instructor, with guides available for each. In most cases, adding a few lines of code will have you seeing traces directly in Agenta.
Next: Prompt Management
We’ve completely rewritten the prompt management SDK, giving you full CRUD capabilities for prompts and configurations. This includes creating, updating, reading history, deploying new versions, and deleting old ones. You can find a first tutorial for this here.
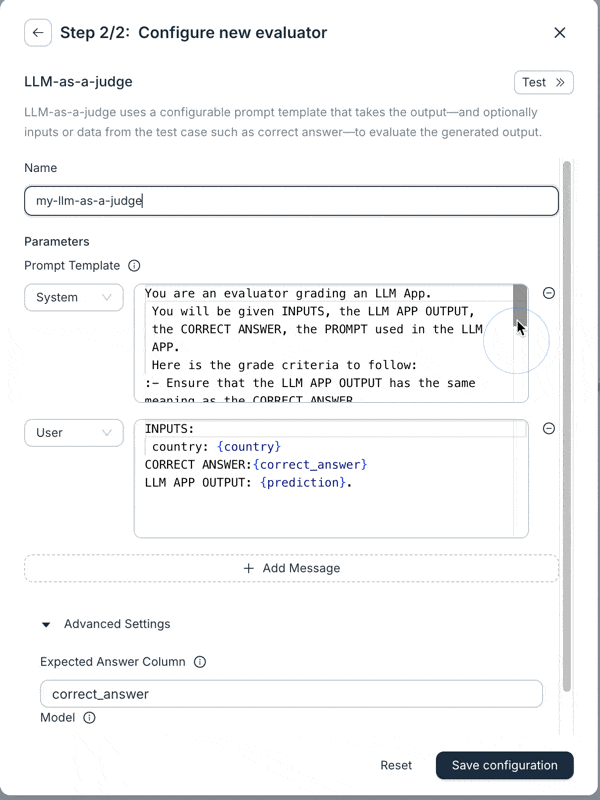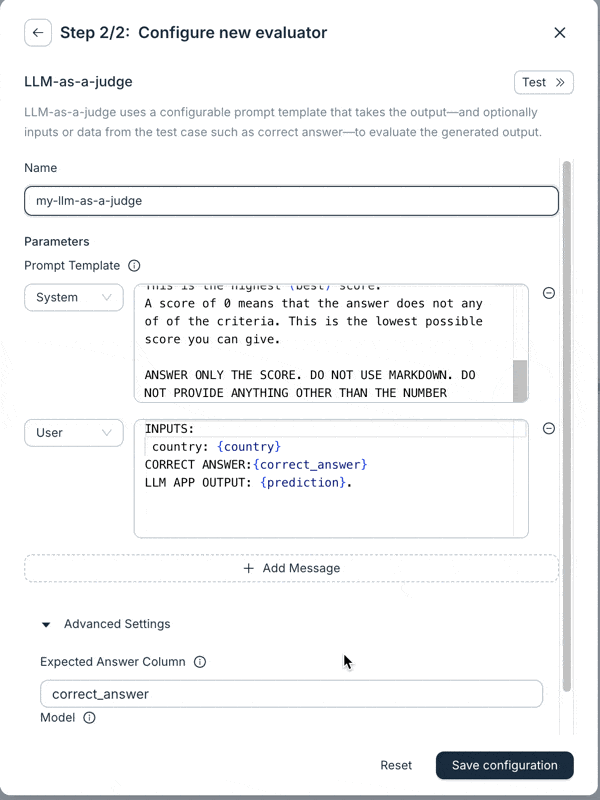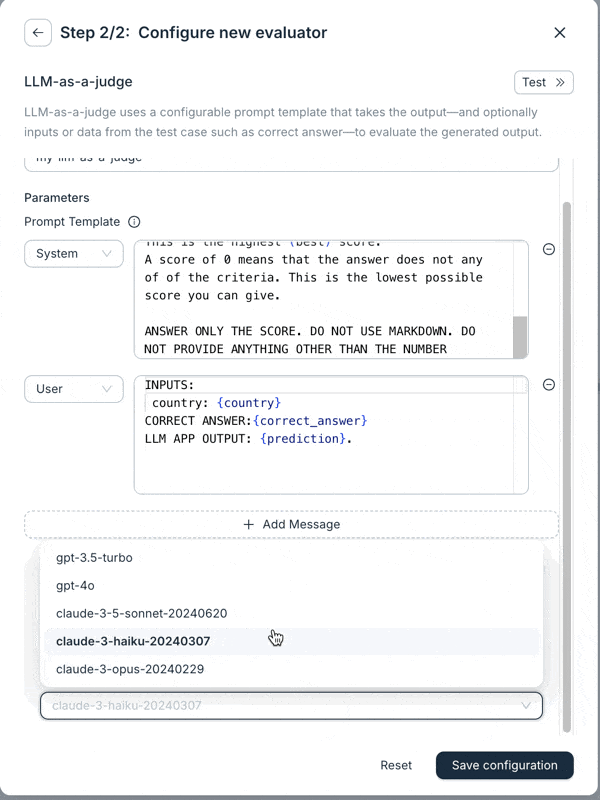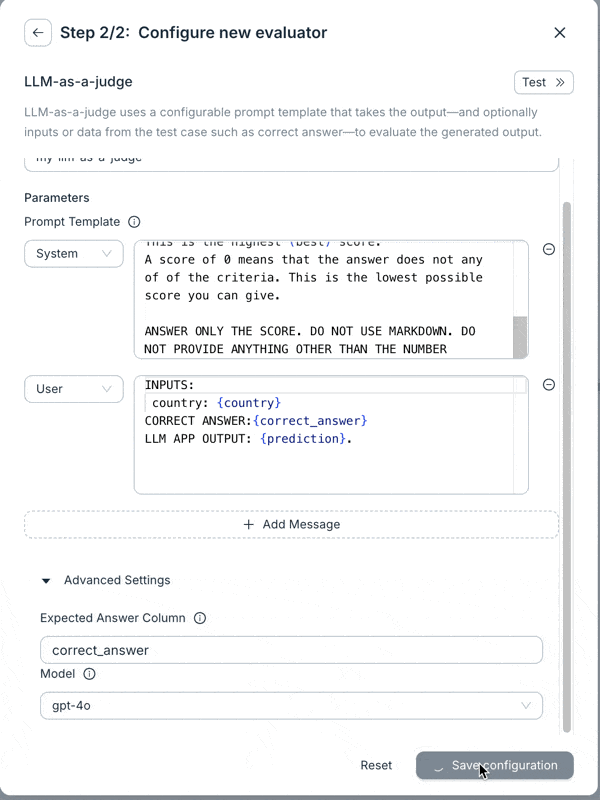
And finally: LLM-as-a-Judge Overhaul
We’ve made significant upgrades to the LLM-as-a-Judge evaluator. It now supports prompts with multiple messages and has access to all variables in a test case. You can also switch models (currently supporting OpenAI and Anthropic). These changes make the evaluator much more flexible, and we’re seeing better results with it.