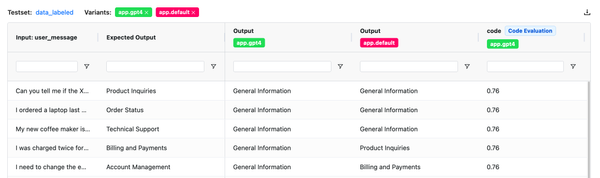
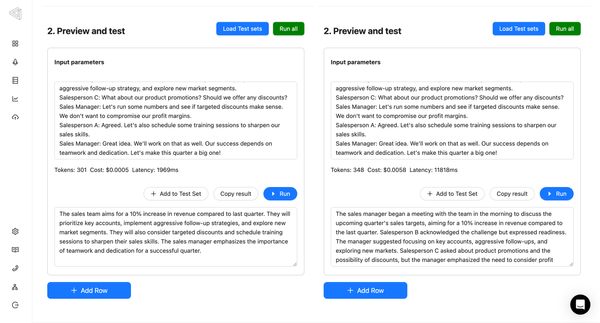
Prompt Versioning
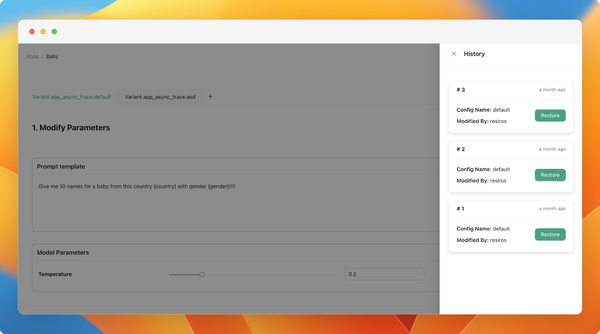
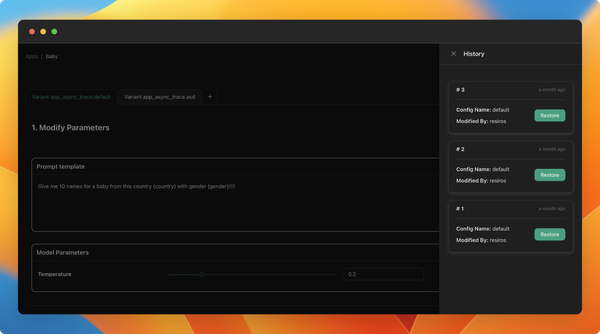
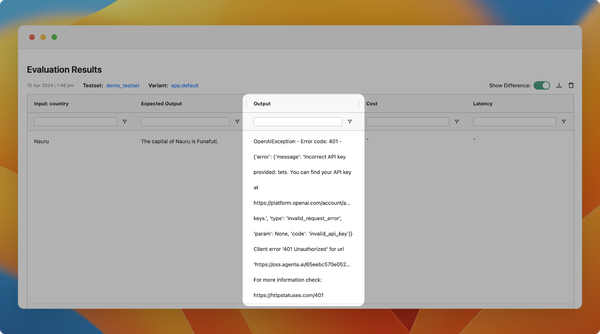
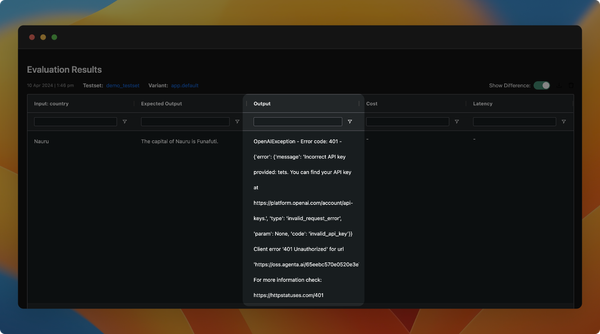
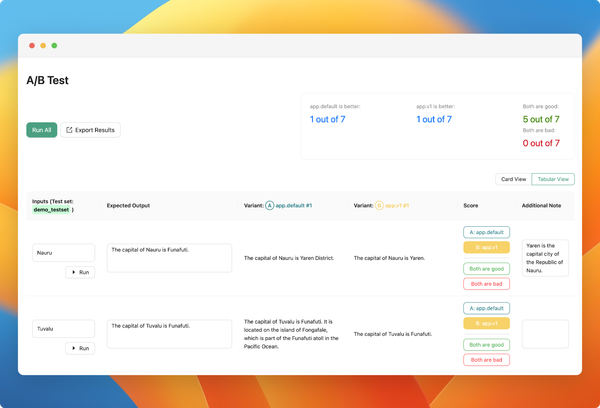
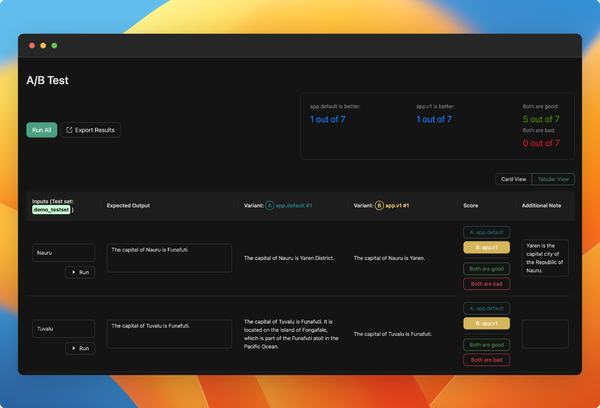
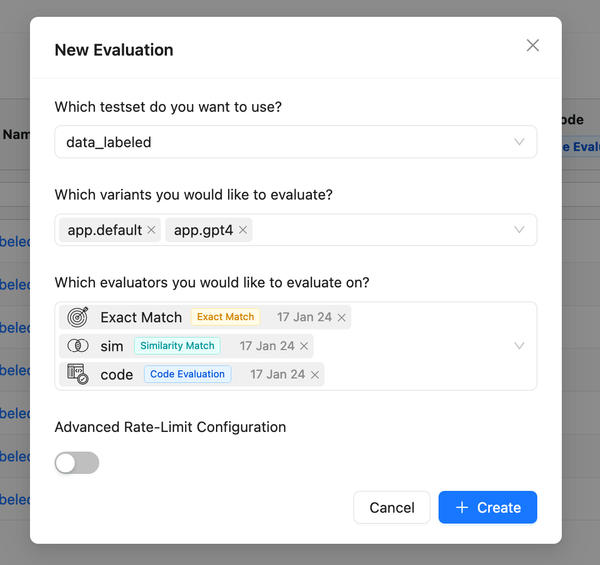
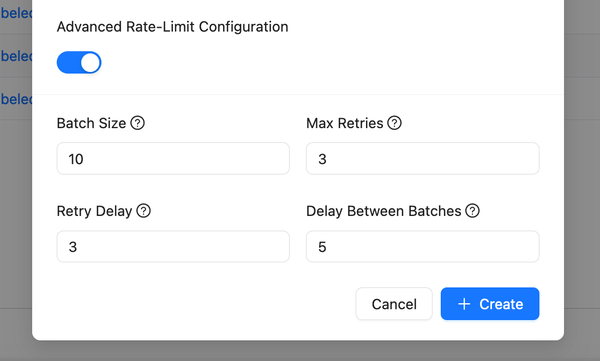
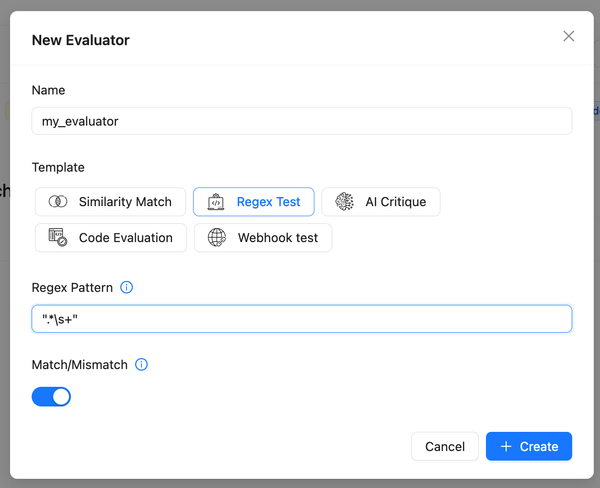
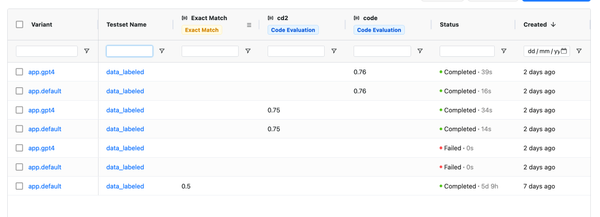
We've introduced the feature to version prompts, allowing you to track changes made by the team and revert to previous versions. To view the change history of the configuration, click on the sign in the playground to access all previous versions.