Revamping evaluation
We've spent the past month re-engineering our evaluation workflow. Here's what's new:
Running Evaluations
- Simultaneous Evaluations: You can now run multiple evaluations for different app variants and evaluators concurrently.
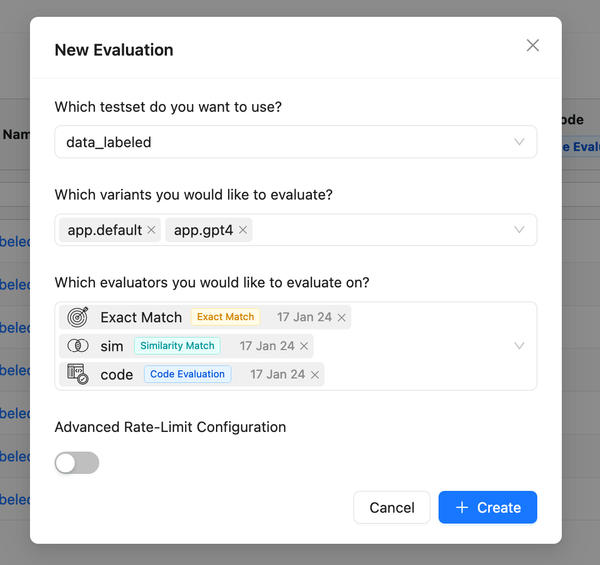
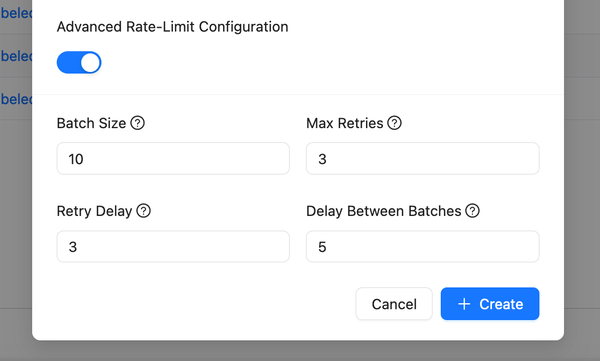
- Rate Limit Parameters: Specify these during evaluations and reattempts to ensure reliable results without exceeding open AI rate limits.
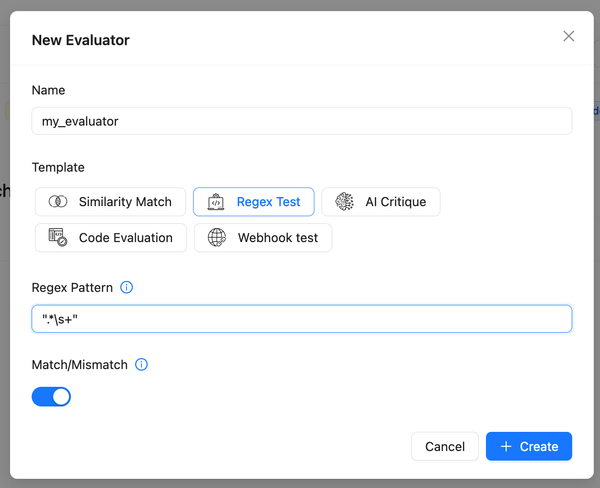
- Reusable Evaluators: Configure evaluators such as similarity match, regex match, or AI critique and use them across multiple evaluations.
Evaluation Reports
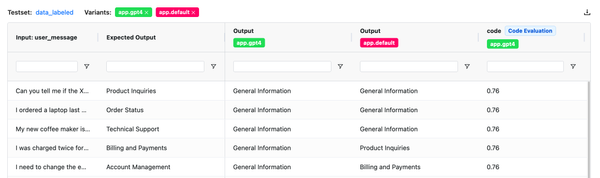
- Dashboard Improvements: We've upgraded our dashboard interface to better display evaluation results. You can now filter and sort results by evaluator, test set, and outcomes.
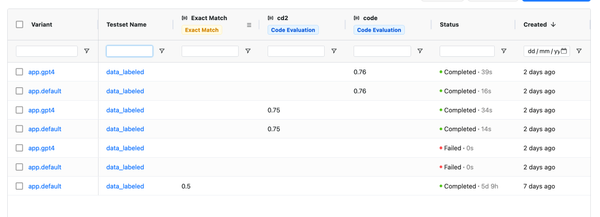
- Comparative Analysis: Select multiple evaluation runs and view the results of various LLM applications side-by-side.