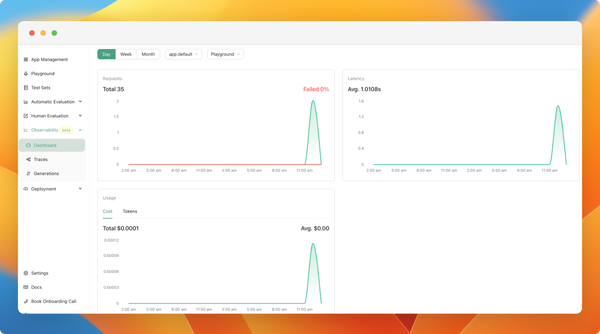
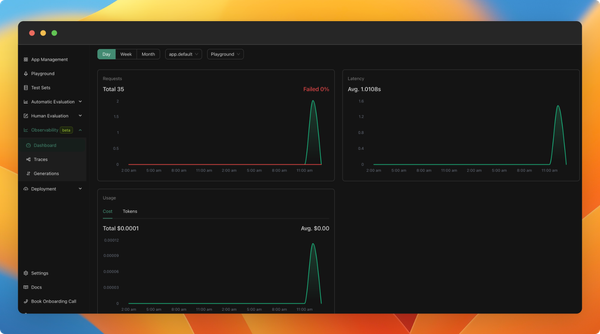
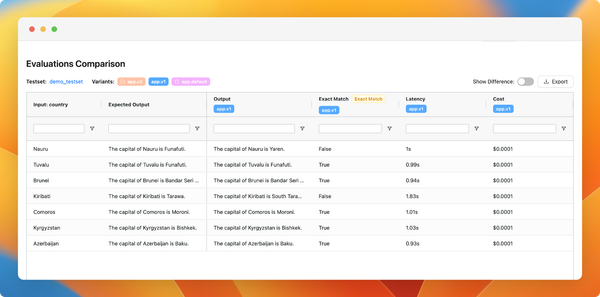
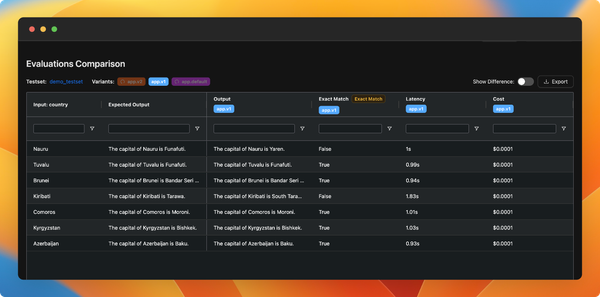
You can now monitor your application usage in production. We've added a new observability feature (currently in beta), which allows you to:
- Monitor cost, latency, and the number of calls to your applications in real-time.
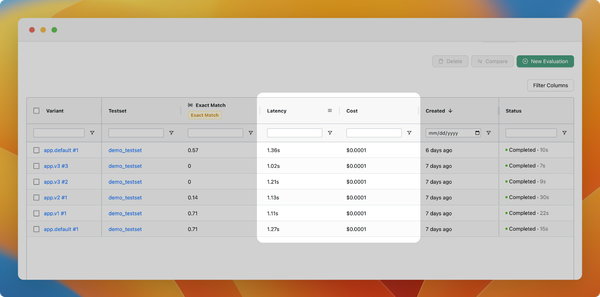
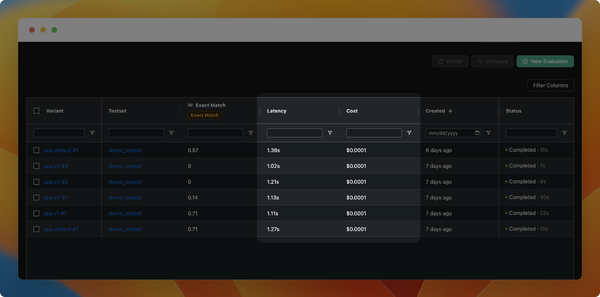
- View the logs of your LLM calls, including inputs, outputs, and used configurations. You can also add any interesting logs to your test set.
- Trace your more complex LLM applications to understand the logic within and debug it.
As of now, all new applications created will include observability by default. We are working towards a GA version in the next weeks, which will be scalable and better integrated with your applications. We will also be adding tutorials and documentation about it.
Find examples of LLM apps created from code with observability here.