Evaluator Testing Playground and a New Evaluation View
Many users faced challenges configuring evaluators in the web UI. Some
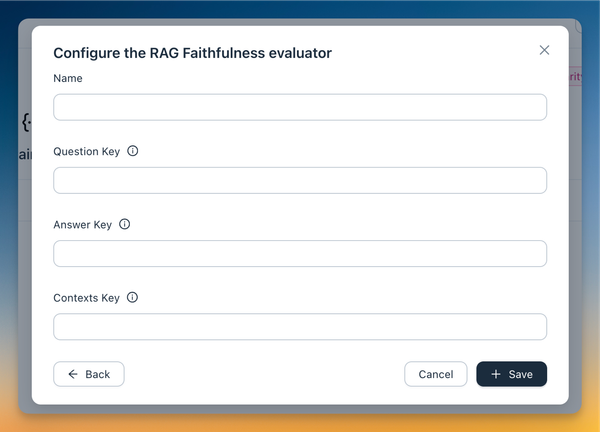
evaluators, such as LLM as a judge, custom code, or RAG evaluators can be
tricky to set up correctly on the first try. Until now, users needed to setup,
run an evaluation, check the errors, then do it again.
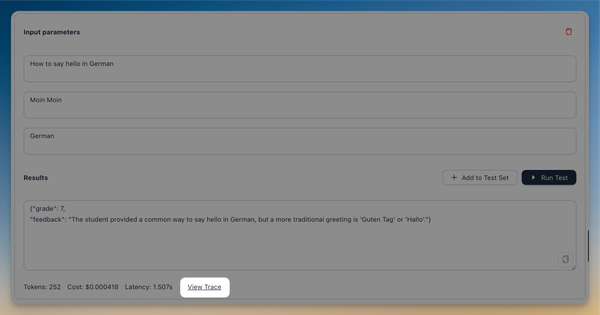
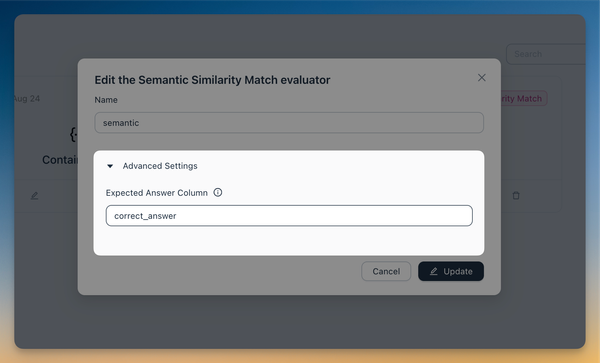
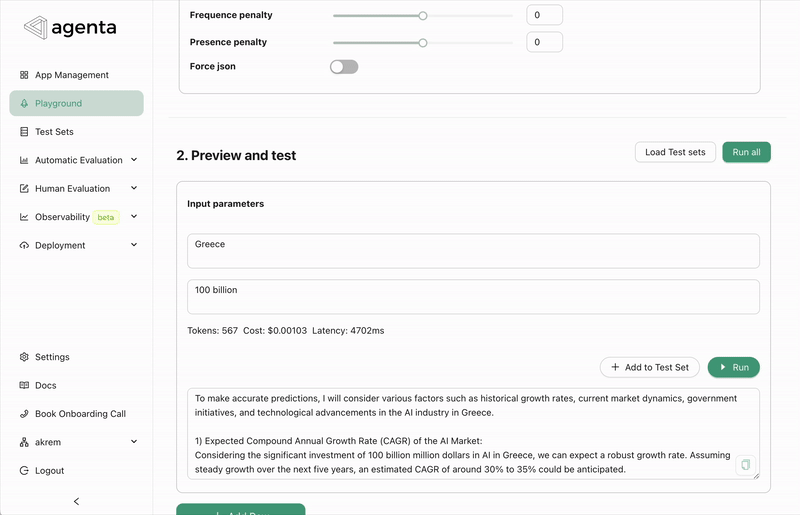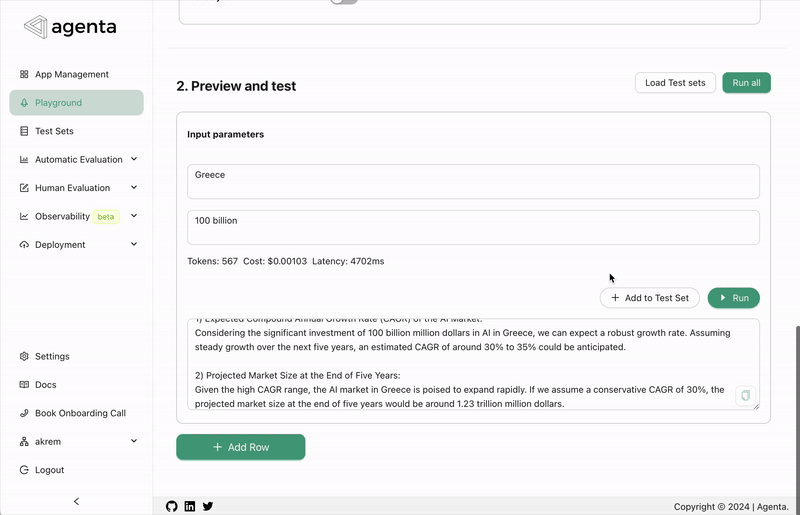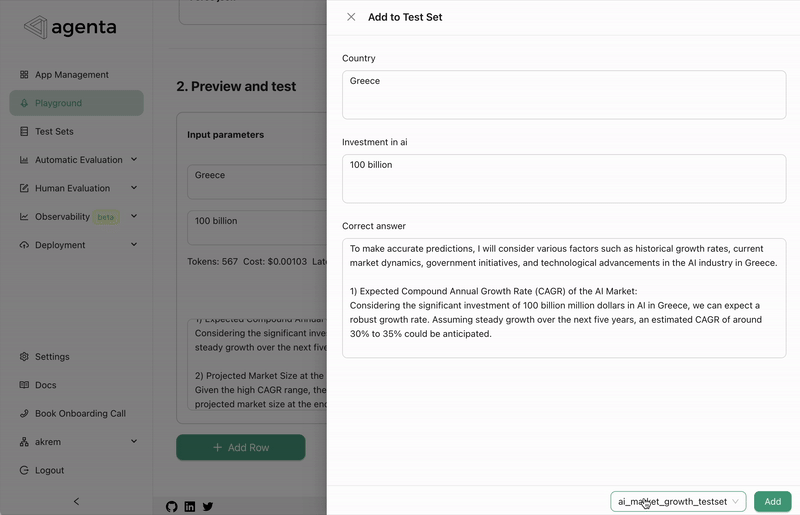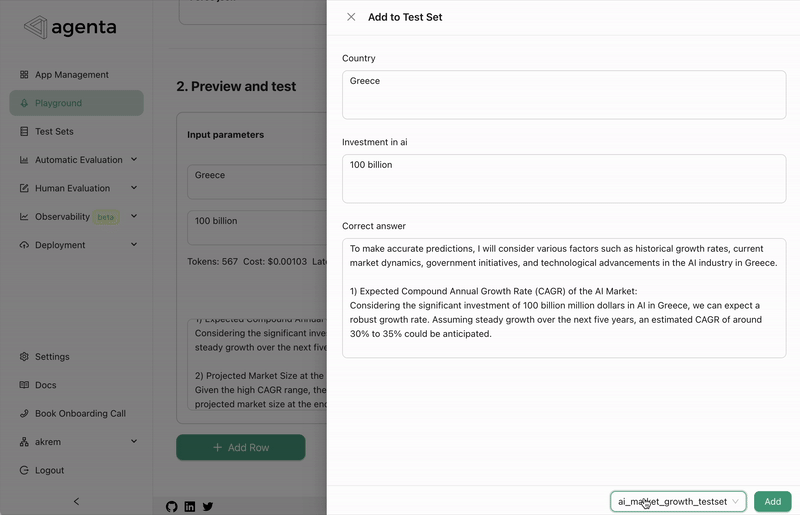
To address this, we've introduced a new evaluator test/debug playground. This feature allows you to test the evaluator live on real data, helping you test the configuration before committing to it and using it for evaluations.
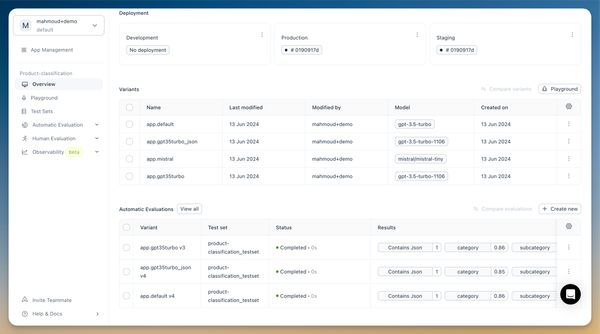
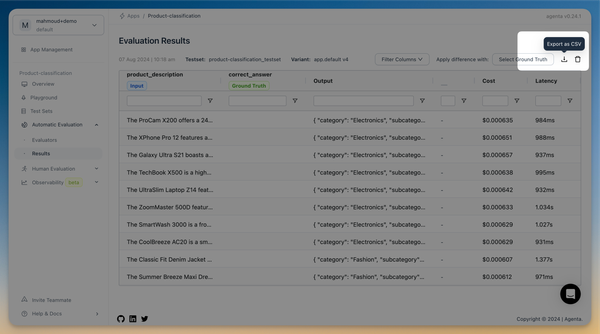
Additionally, we have improved and redesigned the evaluation view. Both automatic and human evaluations are now within the same view but in different tabs. We're moving towards unifying all evaluator results and consolidating them in one view, allowing you to quickly get an overview of what's working.