More Reliable Evaluations
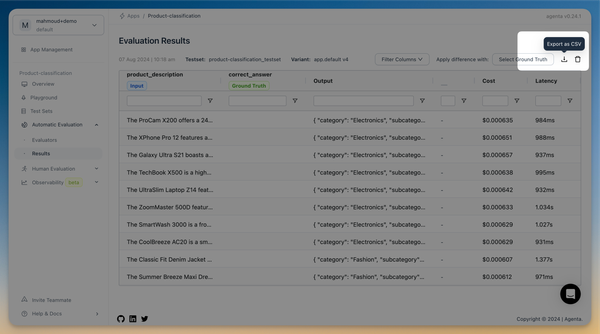
We have worked extensively on improving the reliability of evaluations. Specifically:
- We improved the status for evaluations and added a new
Queuedstatus - We improved the error handling in evaluations. Now we show the exact error message that caused the evaluation to fail.
- We fixed issues that caused evaluations to run infinitely
- We fixed issues in the calculation of scores in human evaluations.
- We fixed small UI issues with large output in human evaluations.
- We have added a new export button in the evaluation view to export the results as a CSV file.
Additionally, we have added a new Cookbook for run evaluation using the SDK.
In observability:
- We have added a new integration with Litellm to automatically trace all LLM calls done through it.
- Now we automatically propagate cost and token usage from spans to traces.