AI-powered Code Reviews
The code for this tutorial is available here.
Please use the SDK version 0.32.0 to run custom workflows. Custom workflows are not compatible with SDK version 0.33.0.
Ever wanted your own AI assistant to review pull requests? In this tutorial, we'll build one from scratch and take it to production. We'll create an AI assistant that can analyze PR diffs and provide meaningful code reviews—all while following LLMOps best practices.
You can try out the final product here. Just provide the URL to a public PR and receive a review from our AI assistant.
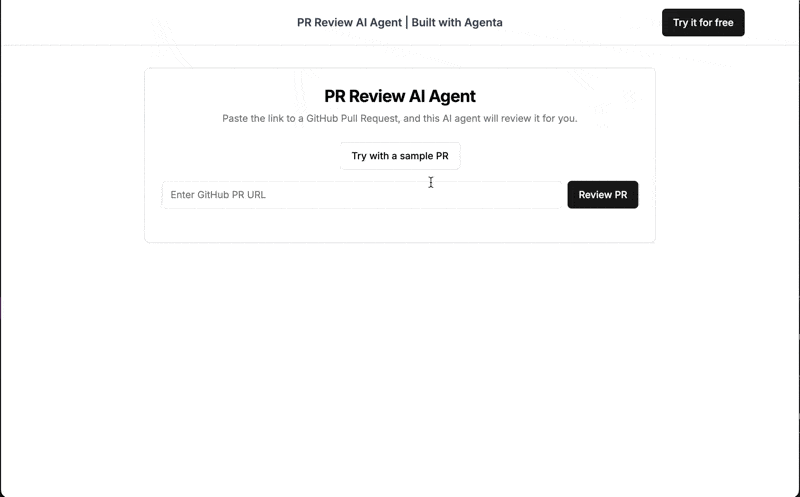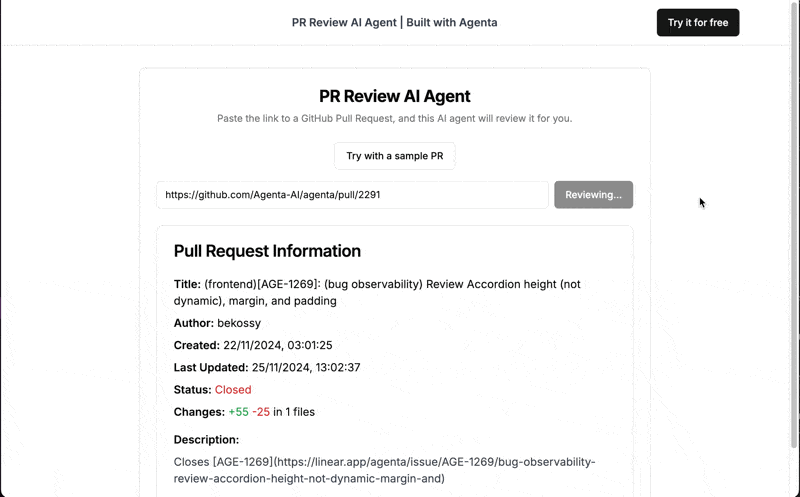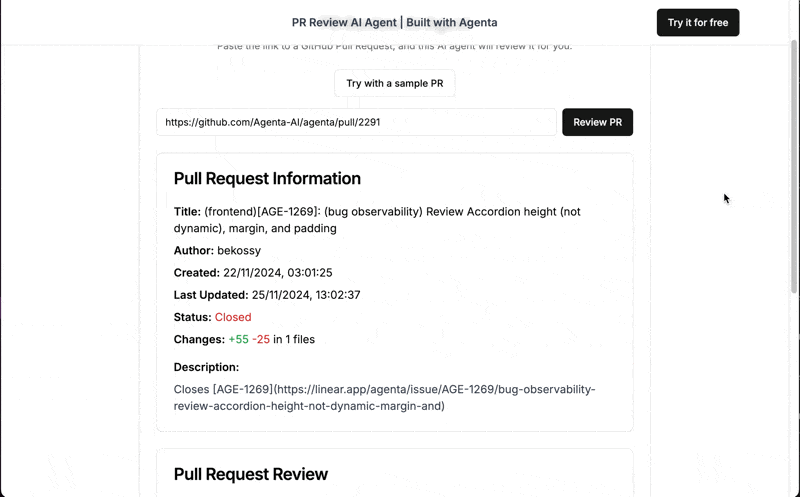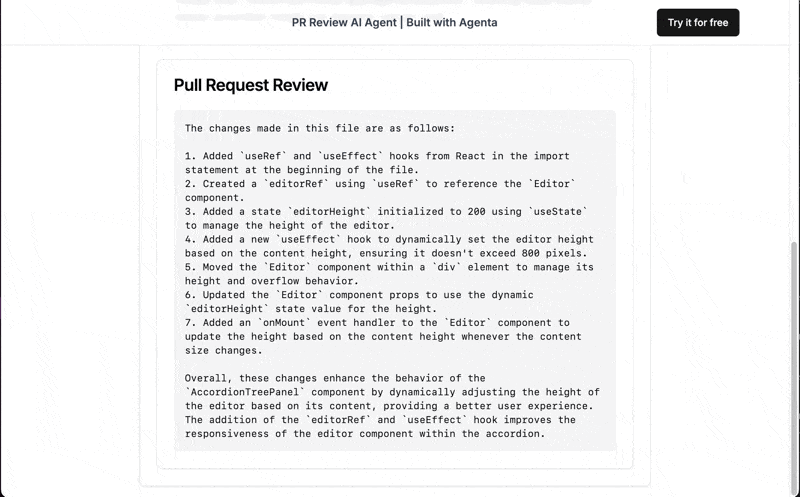
What we'll build
This tutorial walks through creating a production-ready AI assistant. Here's what we'll cover:
- Writing the Code: Fetching the PR diff from GitHub and calling an LLM using LiteLLM.
- Adding Observability: Instrumenting the code with Agenta to debug and monitor our app.
- Prompt Engineering: Refining prompts and comparing different models using Agenta's playground.
- LLM Evaluation: Using LLM-as-a-judge to evaluate prompts and select the best model.
- Deployment: Deploying the app as an API and building a simple UI with v0.dev.
Let's get started!
Writing the core logic
Our AI assistant's workflow is straightforward: When given a PR URL, it fetches the diff from GitHub and passes it to an LLM for review. Let's break this down step by step.
First, we'll fetch the PR diff. GitHub provides this in an easily accessible format:
https://patch-diff.githubusercontent.com/raw/{owner}/{repo}/pull/{pr_number}.diff
Here's a Python function to retrieve the diff:
def get_pr_diff(pr_url):
"""
Fetch the diff for a GitHub Pull Request given its URL.
Args:
pr_url (str): Full GitHub PR URL (e.g., https://github.com/owner/repo/pull/123)
Returns:
str: The PR diff text
"""
pattern = r"github\.com/([^/]+)/([^/]+)/pull/(\d+)"
match = re.search(pattern, pr_url)
if not match:
raise ValueError("Invalid GitHub PR URL format")
owner, repo, pr_number = match.groups()
api_url = f"https://patch-diff.githubusercontent.com/raw/{owner}/{repo}/pull/{pr_number}.diff"
headers = {
"Accept": "application/vnd.github.v3.diff",
"User-Agent": "PR-Diff-Fetcher"
}
response = requests.get(api_url, headers=headers)
response.raise_for_status()
return response.text
Next, we'll use LiteLLM to handle our interactions with language models. LiteLLM provides a unified interface for working with various LLM providers—making it easy to experiment with different models later:
prompt_system = """
You are an expert Python developer performing a file-by-file review of a pull request. You have access to the full diff of the file to understand the overall context and structure. However, focus on reviewing only the specific hunk provided.
"""
prompt_user = """
Here is the diff for the file:
{diff}
Please provide a critique of the changes made in this file.
"""
def generate_critique(pr_url: str):
diff = get_pr_diff(pr_url)
response = litellm.completion(
model=config.model,
messages=[
{"content": config.system_prompt, "role": "system"},
{"content": config.user_prompt.format(diff=diff), "role": "user"},
],
)
return response.choices[0].message.content
Adding observability
Observability is crucial for understanding and improving LLM applications. It helps you track inputs, outputs, and the information flow, making debugging easier. We'll use Agenta for this purpose.
First, we initialize Agenta and set up LiteLLM callbacks. The callback automatically instruments all the LiteLLM calls:
import agenta as ag
ag.init()
litellm.callbacks = [ag.callbacks.litellm_handler()]
Then we add instrumentation decorators to both functions (generate_critique and get_pr_diff) to capture their inputs and outputs. Here's how it looks for the generate_critique function:
@ag.instrument()
def generate_critique(pr_url: str):
diff = get_pr_diff(pr_url)
config = ag.ConfigManager.get_from_route(schema=Config)
response = litellm.completion(
model=config.model,
messages=[
{"content": config.system_prompt, "role": "system"},
{"content": config.user_prompt.format(diff=diff), "role": "user"},
],
)
return response.choices[0].message.content
To set up Agenta, we need to set the environment variable AGENTA_API_KEY (which you can find here) and optionally AGENTA_HOST if we're self-hosting.
We can now run the app and see the traces in Agenta.
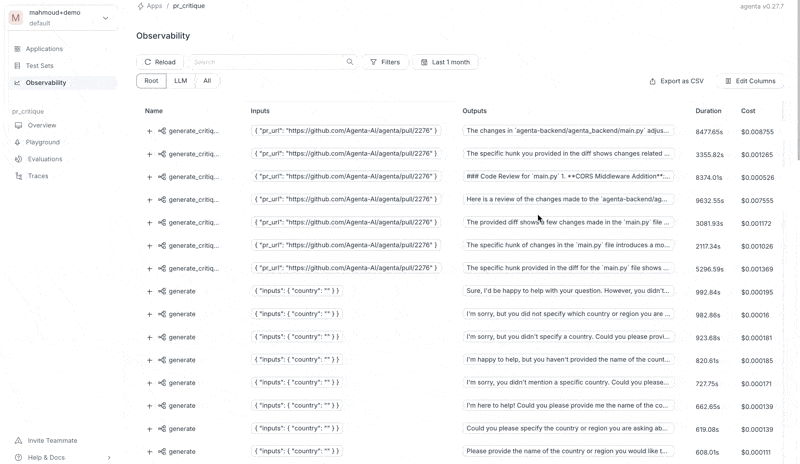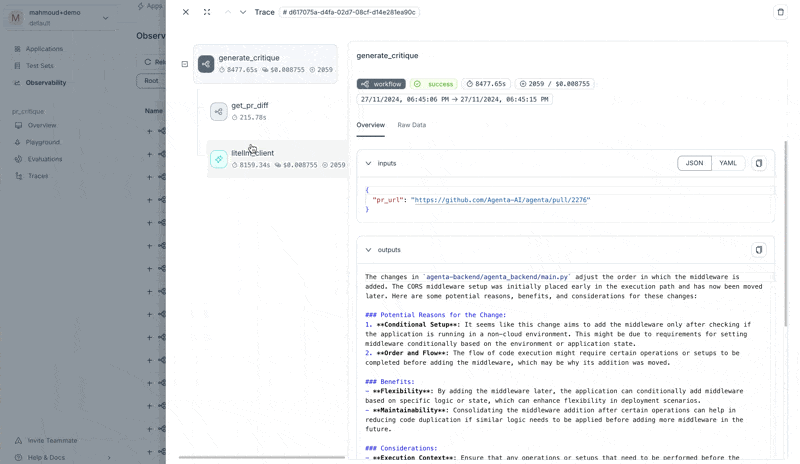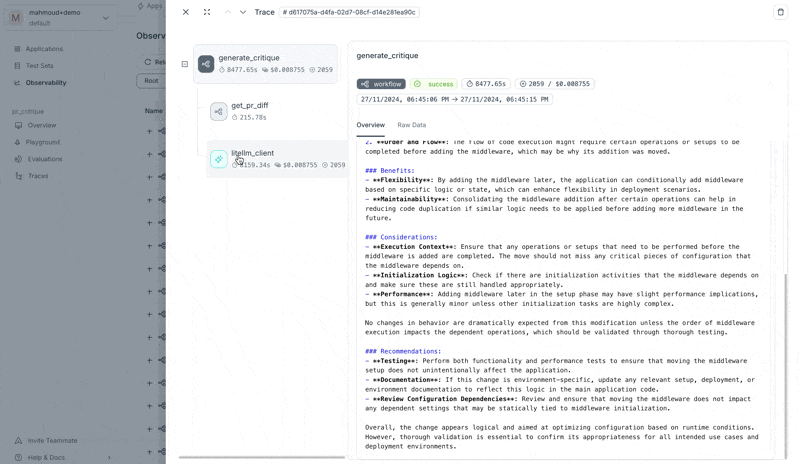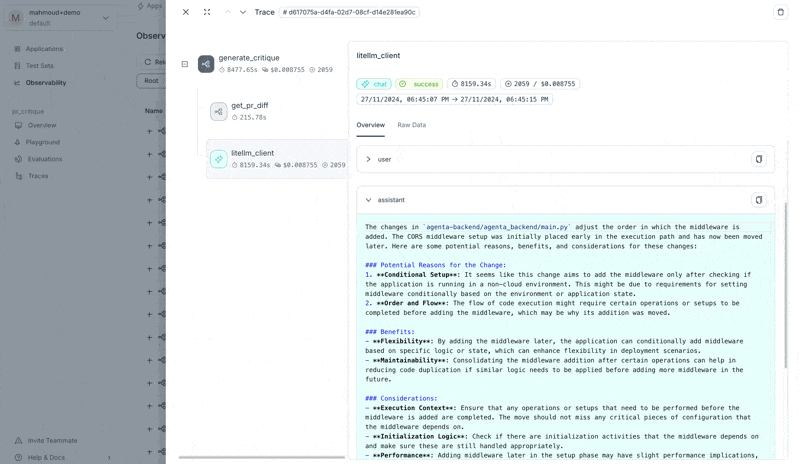
Creating an LLM playground
Now that we have our POC, we need to iterate on it and make it production-ready. This means experimenting with different prompts and models, setting up evaluations, and versioning our configuration.
Agenta custom workflow feature lets us create an IDE-like playground for our AI-assistant workflow.
We'll add a few lines of code to create an LLM playground for our application. This will enable us to version the configuration, run end-to-end evaluations, and deploy the last versions in one click.
Here's the modified code:
import os
import requests
import re
import sys
from urllib.parse import urlparse
from pydantic import BaseModel, Field
import agenta as ag
import litellm
from agenta.sdk.assets import supported_llm_models
from agenta.sdk.types import MCField
#os.environ["AGENTA_API_KEY"] = "your_api_key"
ag.init()
litellm.drop_params = True
litellm.callbacks = [ag.callbacks.litellm_handler()]
prompt_system = """
You are an expert Python developer performing a file-by-file review of a pull request. You have access to the full diff of the file to understand the overall context and structure. However, focus on reviewing only the specific hunk provided.
"""
prompt_user = """
Here is the diff for the file:
{diff}
Please provide a critique of the changes made in this file.
"""
class Config(BaseModel):
system_prompt: str = prompt_system
user_prompt: str = prompt_user
model: str = MCField(default="gpt-3.5-turbo", choices=supported_llm_models)
@ag.route("/", config_schema=Config)
@ag.instrument()
def generate_critique(pr_url:str):
diff = get_pr_diff(pr_url)
config = ag.ConfigManager.get_from_route(schema=Config)
response = litellm.completion(
model=config.model,
messages=[
{"content": config.system_prompt, "role": "system"},
{"content": config.user_prompt.format(diff=diff), "role": "user"},
],
)
return response.choices[0].message.content
Let's break it down:
Defining the configuration and the layout of the playground
from pydantic import BaseModel, Field
from agenta.sdk.types import MCField
from agenta.sdk.assets import supported_llm_models
class Config(BaseModel):
system_prompt: str = prompt_system
user_prompt: str = prompt_user
model: str = MCField(default="gpt-3.5-turbo", choices=supported_llm_models)
To integrate our code in Agenta, we first define the configuration schema. This helps Agenta understand the inputs and outputs of our function and create a playground for it. The configuration defines the playground's layout: the system and user prompts (str) appear as text areas, and the model appears as a multi-select dropdown (note that supported_llm_models is variable in the Agenta SDK that contains a dictionary of providers and their supported models).
Creating the entrypoint
We'll adjust our function to use the configuration. @ag.route creates an API endpoint for our function with the configuration schema we defined. This endpoint will be used by Agenta's playground, evaluation, and the deployed API to interact with our application.
ag.ConfigManager.get_from_route(schema=Config) fetches the configuration from the request sent to that API endpoint.
@ag.route("/", config_schema=Config)
@ag.instrument()
def generate_critique(pr_url: str):
diff = get_pr_diff(pr_url)
config = ag.ConfigManager.get_from_route(schema=Config)
response = litellm.completion(
model=config.model,
messages=[
{"content": config.system_prompt, "role": "system"},
{"content": config.user_prompt.format(diff=diff), "role": "user"},
],
)
return response.choices[0].message.content
Linking the application to Agenta
To connect your application to Agenta, you first need to create a Uvicorn server using the FastAPI app object provided by Agenta.
Add the following snippet to your application:
if __name__ == "__main__":
import uvicorn
uvicorn.run(ag.sdk.decorators.routing.app, host="0.0.0.0", port=8000)
This starts a local server at http://0.0.0.0:8000. To make it accessible from the internet, use a tunneling service like ngrok.
Run the following command to start ngrok:
ngrok http 8000
ngrok will generate a public URL. Navigate to the overview page in Agenta, create a new custom workflow, and enter this URL. You'll then have access to the playground to start interacting with your application.
Evaluating using LLM-as-a-judge
To evaluate the quality of our AI assistant's reviews and compare prompts and models, we need to set up evaluation.
First, we'll create a small test set with publicly available PRs.
Next, we'll set up an LLM-as-a-judge to evaluate the quality of the reviews.
To do this, navigate to the evaluation view, click on "Configure evaluators", then "Create new evaluator" and select "LLM-as-a-judge".
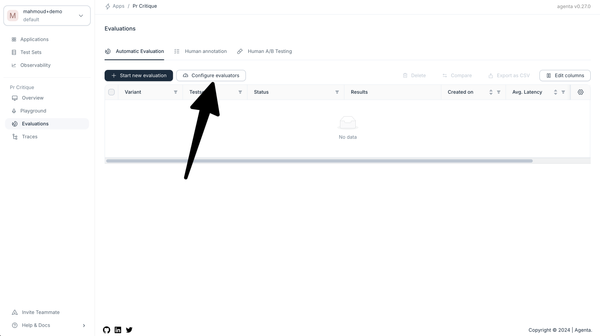
We'll get a playground where we can test different prompts and models for our human evaluator. We use the following system prompt:
CRITERIA:
Technical Accuracy
The reviewer identifies and addresses technical issues, ensuring the PR meets the project's requirements and coding standards.
Code Quality
The review ensures the code is clean, readable, and adheres to established style guides and best practices.
Functionality and Performance
The reviewer provides clear, actionable, and constructive feedback, avoiding vague or unhelpful comments.
Timeliness and Thoroughness
The review is completed within a reasonable timeframe and demonstrates a thorough understanding of the code changes.
SCORE:
-The score should be between 0 and 10
-A score of 10 means that the answer is perfect. This is the highest (best) score.
A score of 0 means that the answer does not any of of the criteria. This is the lowest possible score you can give.
ANSWER ONLY THE SCORE. DO NOT USE MARKDOWN. DO NOT PROVIDE ANYTHING OTHER THAN THE NUMBER
For the user prompt, we'll use the following:
LLM APP OUTPUT: {prediction}
Note that the evaluator accesses the LLM app's output through the {prediction} variable. We can iterate on the prompt and test different models in the evaluator test view.
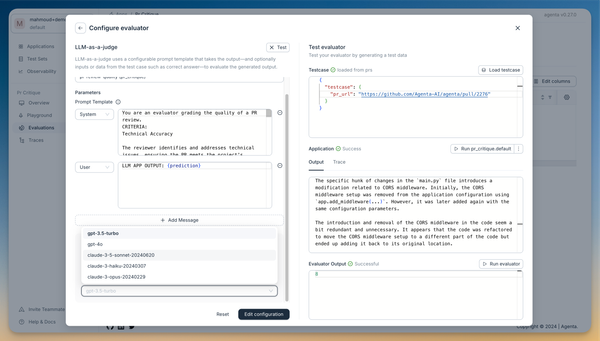
With our evaluator set up, we can run experiments and compare different prompts and models. In the playground, we can create multiple variants and run batch evaluations using the pr-review-quality LLM-as-a-judge.
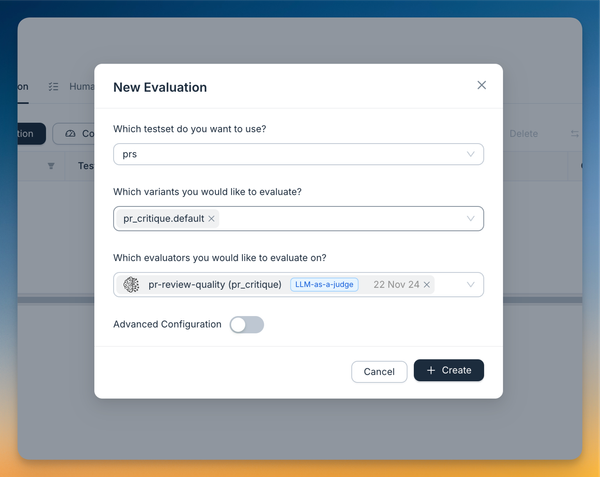
After comparing models, we found similar performance across the board. Given this, we chose GPT-3.5-turbo for its optimal balance of speed and cost.
Deploying to production
Deployment is straightforward with Agenta:
- Navigate to the overview page
- Click the three dots next to your chosen variant
- Select "Deploy to Production"
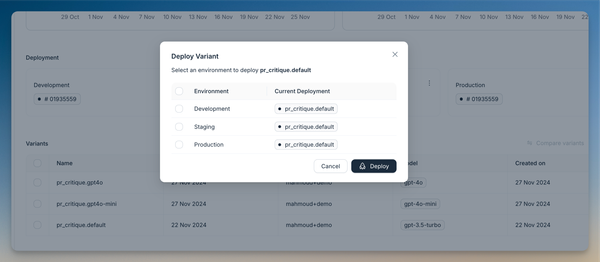
This gives you an API endpoint ready to use in your application.
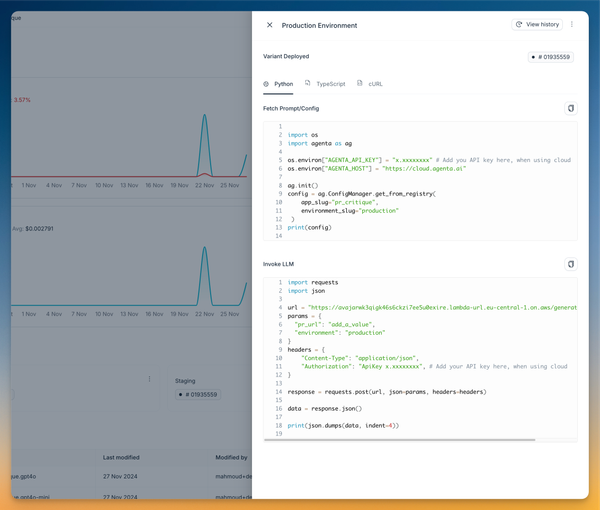
Agenta works in both proxy mode and prompt management mode. You can either use Agenta's endpoint or deploy your own app and use the Agenta SDK to fetch the production configuration.
Building the frontend
For the frontend, we used v0.dev to quickly generate a UI. After providing our API endpoint and authentication requirements, we had a working UI in minutes. You can try it yourself: PR Review Assistant.
What's next?
With our AI assistant in production, Agenta continues to provide observability tools. We can continue enhancing it by:
- Refine the Prompt: Improve the language to get more precise critiques.
- Add More Context: Include the full code of changed files, not just the diffs.
- Handle Large Diffs: Break down extensive changes and process them in parts.
Conclusion
In this tutorial, we've:
- Built an AI assistant that reviews pull requests.
- Implemented observability and prompt engineering using Agenta.
- Evaluated our assistant with LLM-as-a-judge.
- Deployed the assistant and connected it to a frontend.