RAG application with LlamaIndex
Retrieval Augmented Generation (RAG) is a very useful architecture for grounding the LLM application with your own knowldge base. However, it is not easy to build a robust RAG application that does not hallucinate and answers truthfully.
In this tutorial, we will show how to use a RAG application built with LlamaIndex. We will create a playground based on the RAG application allowing us to quickly test different configurations in a live playground. Then we will evaluate different variants of the RAG application with the playground.
Let's get started
What are we building?
Our goal is to build a RAG application. The application takes a transcript of a conversation and a question then returns the answer.
We want to quickly iterate on the configuration of the RAG application and evaluate the performance of each configuration.
Here is a list of parameters we would to experiment with in the playground:
- How to split the transcript: the separator, the chunk size, and the overlap, and the text splitter to use in LlamaIndex (
TokenTextSplitterorSentenceSplitter) - The embedding model to be used (
Davinci,Curie,Babbage,ADA,Text_embed_ada_002) - The embedding mode: similarity mode or text search mode
- The LLM model to be used to generate the final response (
gpt3.5-turbo,gpt4...)
After finishing, we will have a playground where we can experiment with these different parameters live, and compare the outputs between different configuration side-by-side.
In addition, we will be able to run evaluations on the different versions to score them, and later deploy the best version to production, without any overhead.
Installation and Setup
First, let's make sure that you have the latest version of agenta installed.
pip install -U agenta
Now let's initialize our project
agenta init
Write the core application
The idea behind agenta is to distangle the core application code from the parameters. So first let's write the core code of the application using some default parameters. Then we will extract the parameters, add them to the configuration and add the agenta lines of codes.
The core application
Let's start by writing a simple application with LlamaIndex.
from llama_index import Document, ServiceContext, VectorStoreIndex
from llama_index.embeddings.openai import (
OpenAIEmbedding,
OpenAIEmbeddingMode,
OpenAIEmbeddingModelType,
)
from llama_index.langchain_helpers.text_splitter import (
TokenTextSplitter,
)
from llama_index.llms import OpenAI
from llama_index.text_splitter import TokenTextSplitter
def answer_qa(transcript: str, question: str):
text_splitter = TokenTextSplitter(
separator="\n",
chunk_size=1024,
chunk_overlap=20,
)
service_context = ServiceContext.from_defaults(
llm=OpenAI(temperature=0.9, model="gpt-3.5-turbo"),
embed_model=OpenAIEmbedding(
mode=OpenAIEmbeddingMode.SIMILARITY_MODE,
model=OpenAIEmbeddingModelType.ADA,
),
node_parser=text_splitter,
)
# build a vector store index from the transcript as message documents
index = VectorStoreIndex.from_documents(
documents=[Document(text=transcript)], service_context=service_context
)
query_engine = index.as_query_engine(
service_context=service_context, response_mode="simple_summarize"
)
response = query_engine.query(question)
return response
if __name__ == "__main__":
with open("transcript", "r") as f:
transcript = f.read()
question = "What do they say about blackfriday?"
response = answer_qa(transcript, question)
print(response)
If you are not familiar with LlamaIndex, I encourage you to read the docs here.
However, here is a quick explanation of what is happening in the code above:
text_splitter = TokenTextSplitter(
separator="\n",
chunk_size=1024,
chunk_overlap=20,
)
service_context = ServiceContext.from_defaults(
llm=OpenAI(temperature=0.9, model="gpt-3.5-turbo"),
embed_model=OpenAIEmbedding(
mode=OpenAIEmbeddingMode.SIMILARITY_MODE,
model=OpenAIEmbeddingModelType.ADA,
),
node_parser=text_splitter,
)
# build a vector store index from the transcript as message documents
index = VectorStoreIndex.from_documents(
documents=[Document(text=transcript)], service_context=service_context
)
This part is responsible for ingesting the data and building the index. We specify how the input text should be split into chunks in the text_splitter, then which model to use for embedding and in the response in service_context.
query_engine = index.as_query_engine(
service_context=service_context, response_mode="simple_summarize"
)
response = query_engine.query(question)
This part is responsible for querying the index and generating the response. We specify the response mode to be simple_summarize which is one of the response modes in LlamaIndex. This response mode Truncates all text chunks to fit into a single LLM prompt.
Basically, we are taking the transcript of the call, chunking it and embedding it, then later querying it using the simple_summarize technique, which first embeds the question, retrieve the most similar chunk, creates a prompt for it and summarize it using the LLM model.
Make it into an agenta application
Now that we have the core application, let's serve it to the agenta platform. In this first step we would not add the parameters yet, we will do that in the next step. We will just add it to agenta to be able to use it in the playground, evaluate it and deploy it.
For this we need three things:
- Modifying the code to initialize agenta and specify the entrypoint to the code (which will be converted to an endpoint)
- Add a requirements.txt file
- Adding the environment variables to a
.envfile
Modifying the code
We just need to add the following lines to initialize agenta and specify the entrypoint to the code (which will be converted to an endpoint)
import agenta as ag
ag.init() # This initializes agenta
@ag.entrypoint()
def answer_qa(transcript: str, question: str):
# the rest of the code
ag.init() initializes agenta while @ag.entrypoint() is a wrapper around Fastapi that creates an entrypoint.
Adding a requirements.txt file
We need to add a requirements.txt file to specify the dependencies of our application. In our case, we need to add llama_index and agenta to the requirements.txt file.
llama_index
agenta
Adding the environment variables to a .env file
We need to add the environment variables to a .env file. In our case, we need to add the following variables:
OPENAI_API_KEY=<your openai api key>
Serving the application to agenta
Finally we need serve the application to agenta. For this we need to run the following command:
pip install -U agenta
agenta init
agenta variant serve app.py
agenta init initializes the llm application in the folder. It creates a config.yaml file that contains the configuration of the application.
agenta variant serve app.py serves the application to agenta. It sends the code to the platform, which builds a docker image and deploy the endpoint. Additionally it is added to the UI.
You should see the following outputs at success of the command:
Congratulations! 🎉
Your app has been deployed locally as an API. 🚀 You can access it here: https:///<id>/.lambda-url.eu-central-1.on.aws/
Read the API documentation. 📚 It's available at: https:///<id>/.lambda-url.eu-central-1.on.aws/docs
Start experimenting with your app in the playground. 🎮 Go to: https://cloud.agenta.ai/apps/<app-id>/playground
Now you can jump to agenta and find a playground where you can interact with the application.
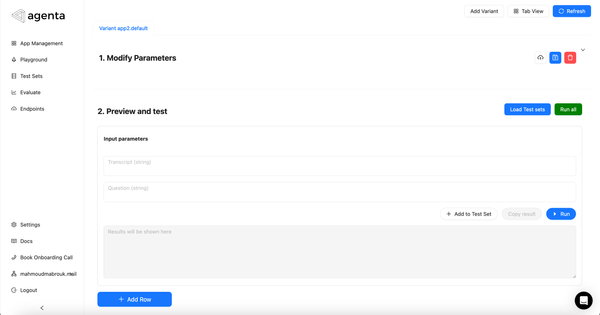
Playground after serving the first version of our RAG application
Adding parameters to the playground
The version we have deployed to the playground does not have any parameters. We can test it, evaluate it, but we cannot modify it and test different configurations.
Let's add a few parameters to the application to improve our playground and serve it again to agenta.
To add a configuration to the application, we just need to register the default in the code after calling agenta.init(). When defining the parameters, we need to provide the type to render them correctly in the playground.
ag.config.register_default(
chunk_size=ag.intParam(1024, 256, 4096),
chunk_overlap=ag.intParam(20, 0, 100),
temperature=ag.intParam(0.9, 0.0, 1.0),
model=ag.MultipleChoiceParam(
"gpt-3.5-turbo", ["gpt-3.5-turbo", "gpt-4", "gpt-4-turbo"]),
response_mode=ag.MultipleChoiceParam(
"simple_summarize", ["simple_summarize", "refine", "compact", "tree_summarize", "accumulate", "compact_accumulate"]),
)
What we did here is to add the parameters, and specify the type of each parameter. intParam are integers with a default value, a minimum, maximum in that order. They are rendered as a slider in the playground. MultipleChoiceParam are multiple choice parameters with a default value and a list of choices. They are rendered as a dropdown in the playground.
We chose here to select the most important parameters in a RAG. The chunk size, the chunk overlap, the temperature of the LLM model, the LLM model itself, and the response mode (you can see the documentation of LlamaIndex for more details about the response mode).
To use the configuration in the code, you use the variable as ag.config.<param_name> anywhere in the code. For instance:
text_splitter = TokenTextSplitter(
separator="\n",
chunk_size=ag.config.chunk_size,
chunk_overlap=ag.config.chunk_overlap,
)
Putting it all together
Here is how our final code looks like:
import agenta as ag
from llama_index import Document, ServiceContext, VectorStoreIndex
from llama_index.embeddings.openai import (
OpenAIEmbedding,
OpenAIEmbeddingMode,
OpenAIEmbeddingModelType,
)
from llama_index.langchain_helpers.text_splitter import (
TokenTextSplitter,
)
from llama_index.llms import OpenAI
from llama_index.text_splitter import TokenTextSplitter
ag.init()
ag.config.register_default(
chunk_size=ag.IntParam(1024, 256, 4096),
chunk_overlap=ag.IntParam(20, 0, 100),
temperature=ag.IntParam(0.9, 0.0, 1.0),
model=ag.MultipleChoiceParam(
"gpt-3.5-turbo", ["gpt-3.5-turbo", "gpt-4", "gpt-4-turbo"]),
response_mode=ag.MultipleChoiceParam(
"simple_summarize", ["simple_summarize", "refine", "compact", "tree_summarize", "accumulate", "compact_accumulate"]),
)
@ag.entrypoint
def answer_qa(transcript: str, question: str):
text_splitter = TokenTextSplitter(
separator="\n",
chunk_size=ag.config.chunk_size,
chunk_overlap=ag.config.chunk_overlap,
)
service_context = ServiceContext.from_defaults(
llm=OpenAI(temperature=ag.config.temperature, model=ag.config.model),
embed_model=OpenAIEmbedding(
mode=OpenAIEmbeddingMode.SIMILARITY_MODE,
model=OpenAIEmbeddingModelType.ADA,
),
node_parser=text_splitter,
)
# build a vector store index from the transcript as message documents
index = VectorStoreIndex.from_documents(
documents=[Document(text=transcript)], service_context=service_context
)
query_engine = index.as_query_engine(
service_context=service_context, response_mode=ag.config.response_mode
)
response = query_engine.query(question)
return response
Now let's serve it to agenta again:
agenta variant serve app.py