Quick Start Evaluation from UI
This quick start guide will help you run your first evaluation using the Agenta UI.
You will create a prompt that classifies tweets based on their sentiment (positive, negative, neutral). Then you will run an evaluation to measure its performance.
Prerequisites
Before you get started, create the prompt and the test set:
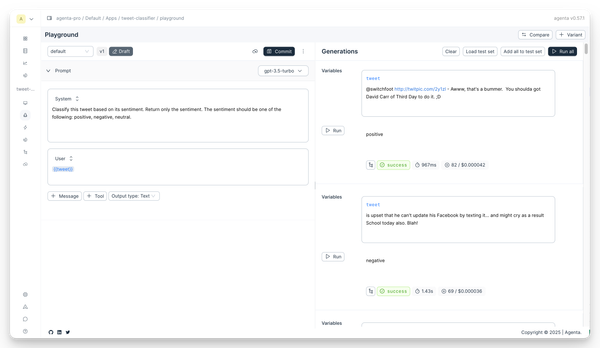
Create the prompt
Create a completion prompt that classifies tweets based on their sentiment.
Use the following prompt:
System prompt
Classify this tweet based on its sentiment. Return only the sentiment. The sentiment should be one of the following: positive, negative, neutral.
User prompt
{{tweet}}
Commit the prompt to the default variant.
Create the test set
Download a test set with 50 tweets based on the Sentiment140 kaggle dataset. Download the test set here. Then upload it to Agenta (see how to upload a test set).
Running the evaluation
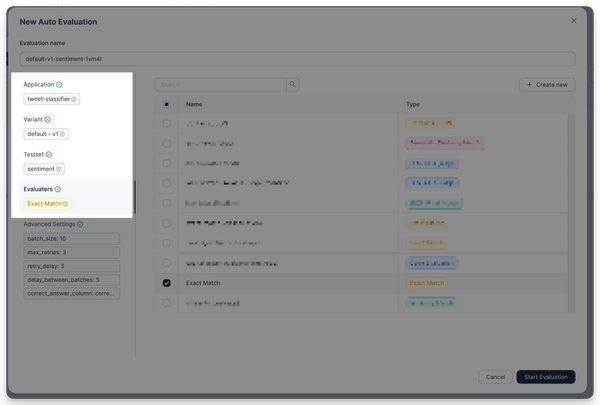
Navigate to the Evaluations page. Click on Start new evaluation.
- Choose the test set
sentiment140_first50. - Choose the latest revision from the default variant.
- Choose the evaluator
Exact Match. - Click on Start evaluation.
Agenta offers a variety of built-in evaluators for most use cases. You can also create custom evaluators in Python. One of the most commonly used evaluators is LLM as a Judge. See more about evaluators.
Viewing the results
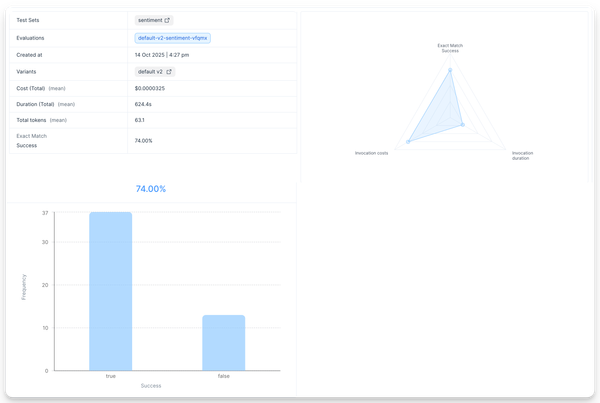
Once the evaluation completes, click on the evaluation run to see the results.
The overview tab shows the aggregated results for all evaluators.
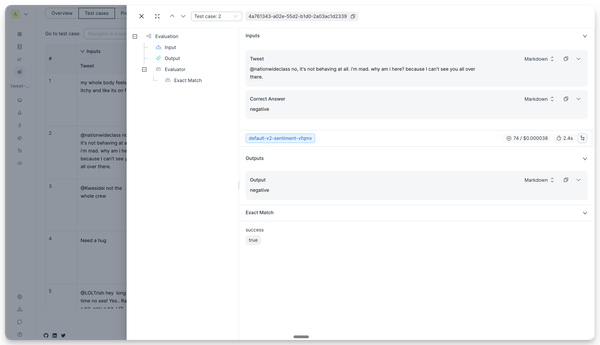
The test set tab shows the results for each test case.
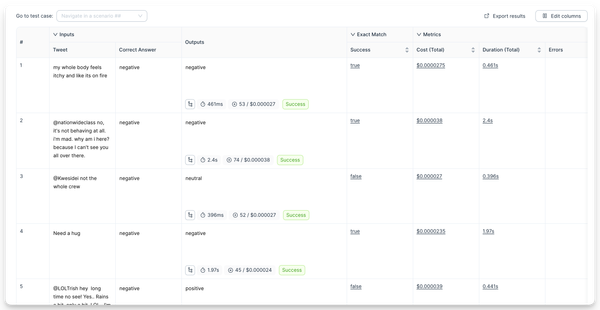
Click the expand button in the top right corner of the output cell to open a drawer with the full output. Click the tree icon to open a drawer with the trace.
Making a change and comparing the results
Make a small change to the prompt and compare the results. Modify the prompt to use gpt-4o-mini instead of gpt-4o. Commit the change. Then rerun the evaluation with the new prompt revision.
Now compare the results between the two evaluations. Click the + Compare button on the top right corner of the evaluation results page. Select the evaluation to compare to.
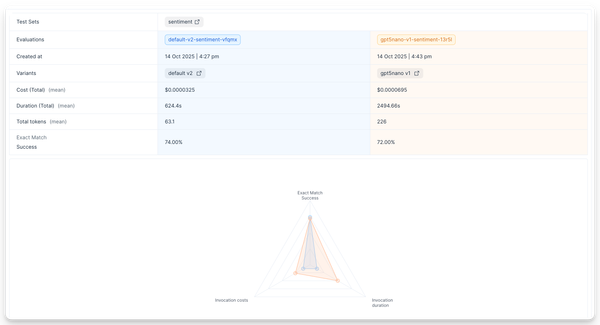
You might find that gpt-4o-mini performs differently than gpt-4o on this task. It may cost less but could have lower accuracy or different latency.
Next steps
You have run a simple evaluation for a classification task in Agenta. Next, learn more about the different evaluators and how to configure them. See more about evaluators.